こんにちは、清水(@_smzst)です。巷で話題の GKE Autopilot について旧来のものと何が違うのか調べ、実際にクラスタを作って挙動を確認してみました。
ちなみに、所属しているチームのプロダクトである CRALY1 は社内で最初の Kubernetes クラスタ(GKE)上で構築されたプロダクトです。
なにが嬉しいのか
ノードとノードプールの管理が不要になり、ワークロードに集中して運用が行えるようになった
Cluster autoscaler, Node auto provisioning によってリソース使用状況などによってよしなにスケールアウトしてくれます。 Cluster autoscaler はノードが、Node auto provisioning はノードプールがスケールアウトするという違いがあります。ノードのデフォルトマシンタイプは e2-medium(2 vCPU, 4 GB)で、このマシンタイプに収まるリソース要求の Pod であれば Cluster autoscaler によってそのままスケールアウトし、これより高いリソースを要求する場合や Tolerations などを指定した Pod の場合は Node auto provisioning によってそれに見合ったマシンタイプあるいは必要に応じて Taints を付与したノードプールを新たに作成してくれます。すご!
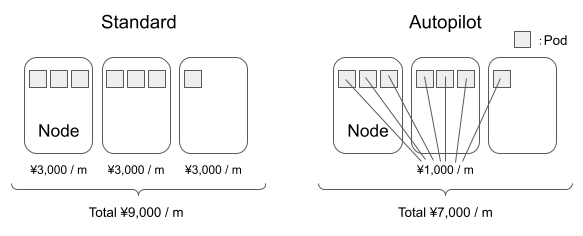
ノードごとの課金だったのが Pod ごとの課金になった
スタンダード環境ではノードごとの課金でしたが、たとえばぎりぎりノードに乗り切らない Pod があったとき、その溢れた Pod 用にノードを丸々プロビジョニングすることになるので費用的に無駄がありました。これが Pod ごとの課金になったのでこのようなケースでも費用が最適化することができます。
スタンダード環境との違いは
以下にリストアップされていますが、この中からいくつかピックアップしつつ説明を補足します。
https://cloud.google.com/kubernetes-engine/docs/concepts/autopilot-overview#comparison
リージョンクラスタのみ
リージョンクラスタとは、1 つのリージョンの複数ゾーンにコントロールプレーンとノードを複製することで可用性を高めたクラスタのこと。コントロールプレーンが冗長構成になっているというところがマルチゾーンクラスタと異なります。
リリースチャンネルの登録が必要
リリースチャンネルには、Rapid(最新のパッチバージョンが使用できる)、Regular(デフォルト。Rapid リリースから 2 ~ 3 ヶ月後)、Stable(Regular リリースから 2 ~ 3 ヶ月後)があります。
イメージは Containerd を含む Container-Optimized OS のみ
このようになった背景として、Kubernetes では Docker の一部機能しか使っていない(イメージをビルドするためのイメージビルダーや、コンテナが動く上で必要なボリューム、ネットワークなどは不要)ため、セキュリティリスクに繋がる余計な機能はないほうがよいためということが考えられます。あとは、Kubernetes が Docker ランタイムをサポートするにあたり、dockershim のメンテナンスの問題が結構あるようです2。
ノードとノードプールがフルマネージド
ノードへのアクセスができないので、ノードのパフォーマンスチューニングが必要なほどの大規模かつ大量のトラフィックを捌くようなシステムには向きません。
Compute Engine API(gcloud compute instance list)では確認できなくなりましたが、kubectl からは確認できるので一覧が見たいケースで困ることはありません。
マシンタイプは e2 のみ。GPU はサポート外
GPU 使いたい場合はスタンダード環境を使いましょう。
セキュリティ的な観点で、Service の spec.externalIPs は使えない
その代わり LoadBalancer タイプの Service を使うか、Ingress を使用して Service を複数のサービス間で共有される外部 IP に追加することで回避可能です。
QoS Class は Guaranteed であること(request, limit が同じ)
request と limit がかけ離れた値になることは悪手と言われているので特に困ることはなさそうです。
向いているユースケース
- バッチ処理
- 負荷の波が大きくないシステム
- ノードをあらかじめたくさん用意して負荷のスパイクに対して高速に Pod をスケールアウトさせることはできない(一応工夫すればできなくはない 3)。Pod よりノードのスケールアウトには時間がかかるので、オートスケールにスピードを要求しないシステムの方が向きます。
- 大規模かつ大量のトラフィックを捌かないシステム
- 先述の通り。
- ステートレスアプリケーション
- 自動アップグレードが必須(リリースチャンネルへの登録が必要)なので、Pod が状態を持っていない方がサービス影響が少ないため。
ちなみに CRALY では、1, 2 のユースケースに完全にマッチしています。
Autopilot を試してみる
代表的な以下の 3 つの挙動を、実際に Autopilot モードでクラスタを作成して確認します。
- Cluster autoscaler
- Node auto provisioning
- e2-medium でホストできないくらいリソース要求の大きな Pod
- ノードセレクタを指定した Pod
Autopilot モードでのクラスタの作成は非常に簡単で、Kubernetes Engine タブから Autopilot モードを選択し、以下のようにクラスタ名とリージョンを選ぶだけです(もちろん詳細な設定を入力することもできます)。
または、gcloud コマンドラインツールからも作成できます。以下のコマンドで Autopilot モードでのクラスタを構築することができます。--enable-private-nodes オプションを追加すると外部 IP アドレスを持たない限定公開クラスタとして作成できますが、Cloud NAT の作成が必要になります(限定公開クラスタについての説明を省略します)。
そのほかに指定できるオプションは「Autopilot クラスタの作成」をご確認ください。
$ gcloud container clusters create-auto $CLUSTER_NAME \
--region $REGION \
--project $PROJECT_ID
5 分ほど待つと Ready になります。作成されたクラスタのノードを確認すると、たしかに e2-medium タイプのインスタンスが立ち上がっています。
$ kubectl get nodes -L beta.kubernetes.io/instance-type NAME STATUS ROLES AGE VERSION INSTANCE-TYPE gk3-autopilot-cluster-1-default-pool-6f27b435-4fcb Ready <none> 31m v1.18.15-gke.1501 e2-medium gk3-autopilot-cluster-1-default-pool-fd4563d1-9pmk Ready <none> 31m v1.18.15-gke.1501 e2-medium
今回はこちらのありふれたマニフェストファイルをベースに挙動を確認してみます。spec.replicas が 1 であり、要求するリソースは 0.25 vCPU かつ 1 GiB ですから 2 台の e2-medium インスタンスに乗り切ることは明らかです。
apiVersion: apps/v1 kind: Deployment metadata: name: nginx spec: selector: matchLabels: app: nginx replicas: 1 template: metadata: labels: app: nginx spec: containers: - name: nginx image: nginx:1.19 resources: requests: cpu: "250m" memory: "1Gi" ports: - containerPort: 80
Cluster autoscaler
上のマニフェストファイルの spec.replicas を 6 にした状態で適用すると、要求するリソースは 6 GiB かつ 1.5 vCPU なので、2 台の e2-medium インスタンスには乗り切りません。このようなケースでは Cluster autoscaler により同じインスタンスタイプのノードがスケールアウトします。
$ kubectl get nodes -L beta.kubernetes.io/instance-type NAME STATUS ROLES AGE VERSION INSTANCE-TYPE gk3-autopilot-cluster-1-default-pool-6f27b435-4fcb Ready <none> 59m v1.18.15-gke.1501 e2-medium gk3-autopilot-cluster-1-default-pool-6f27b435-dvph Ready <none> 45s v1.18.15-gke.1501 e2-medium gk3-autopilot-cluster-1-default-pool-6f27b435-xmwm Ready <none> 45s v1.18.15-gke.1501 e2-medium gk3-autopilot-cluster-1-default-pool-fd4563d1-1x9l Ready <none> 38s v1.18.15-gke.1501 e2-medium gk3-autopilot-cluster-1-default-pool-fd4563d1-9pmk Ready <none> 59m v1.18.15-gke.1501 e2-medium
Node auto provisioning(e2-medium でホストできない Pod)
次は、e2-medium タイプのインスタンスに乗り切らないほど要求するリソースの大きな Pod を作成してみましょう。上記マニフェストファイルの resources.requests.cpu, resources.requests.memory をそれぞれ 2000m, 4Gi として適用します。
インスタンスタイプが e2-standard-4(4 vCPU, 16 GB)のノードがプロビジョニングされました。これが Node auto provisioning です。賢いですね。
$ kubectl get nodes -L beta.kubernetes.io/instance-type NAME STATUS ROLES AGE VERSION INSTANCE-TYPE gk3-autopilot-cluster-1-default-pool-6f27b435-4fcb Ready <none> 66m v1.18.15-gke.1501 e2-medium gk3-autopilot-cluster-1-default-pool-fd4563d1-9pmk Ready <none> 66m v1.18.15-gke.1501 e2-medium gk3-autopilot-cluster-1-nap-2lsiv08s-74dad2a1-p0t4 Ready <none> 3m33s v1.18.15-gke.1501 e2-standard-4
Node auto provisioning(ノードセレクタを指定した Pod)
最後に、Tolerations を指定した Pod によって Taints が付与されたノードが自動でプロビジョニングされることを確認… したかったのですが、どうやっても Taints が付与されたノードがプロビジョニングされてくれませんでした(汚れを許容する Pod とはいえ、わざわざ汚したノードを提供しないか…)。もしできた方いらっしゃったら教えてください。
Autopilot モードでは、Tolerations はワークロードを分離する目的でのみ利用可能です。こちらのリンクにあるサンプルの定義を真似て挙動を確認してみましょう。
手元のクラスタでは asia-northeast1-a, asia-northeast1-c のゾーンにそれぞれ 1 ノードずつ立っていましたので、asia-northeast1-b に配置されるような条件を指定しました4。上記マニフェストファイルの template.spec 配下に以下の記述を追加して適用します。
tolerations: - key: key1 operator: Equal value: value1 effect: NoSchedule nodeSelector: topology.kubernetes.io/zone: asia-northeast1-b
このように asia-northeast1-b ゾーンにノードが立ちました。先述の通り Tolerations は指定しても Taints は付与されていませんでした。
$ kubectl get nodes -L beta.kubernetes.io/instance-type,topology.kubernetes.io/zone NAME STATUS ROLES AGE VERSION INSTANCE-TYPE ZONE gk3-autopilot-cluster-1-default-pool-6f27b435-4fcb Ready <none> 75m v1.18.15-gke.1501 e2-medium asia-northeast1-a gk3-autopilot-cluster-1-default-pool-fd4563d1-9pmk Ready <none> 75m v1.18.15-gke.1501 e2-medium asia-northeast1-c gk3-autopilot-cluster-1-nap-jdhqqvez-cc709963-p6wd Ready <none> 2m02s v1.18.15-gke.1501 e2-medium asia-northeast1-b
さいごに
このような感じで、ノードのことを気にせずにワークロードに集中して運用を行えそうなことが分かっていただけたかと思います。スタンダードモードと比べると制限されることがいくつかありましたが、セキュリティを考慮した結果であったりスムーズな運用が行えるようベストプラクティスを積極的に採用しているためです。
運用で苦労するから Kubernetes でないといけない理由がないならやめとけ!みたいな話を聞いたり聞かなかったりしてきましたが、Autopilot モードを使えば気軽に始めやすくかつ運用しやすくなるのではないでしょうか。
-
CRALY は主要媒体を横断してクリエイティブ軸のレポートを閲覧、分析ができるツールです。レポート工数の削減や効果のよいクリエイティブの訴求軸の特定、クリエイティブ PDCA でお困りの方は https://service.craly.jp/ もご確認ください!↩
-
詳細が気になる人は https://thinkit.co.jp/article/18024 をご参照ください。↩
-
PriorityClass で最低の優先度を割り当てた Pod(Balloon pod)をノードに配置して予めスケールアウトさせておき、負荷に応じて Balloon pod がメインの Pod に置き換わることでノードのスケールアウトに時間を要さずに高速でスケーリングさせる方法。https://wdenniss.com/gke-autopilot-spare-capacity↩
-
Autopilot モードでノードセレクタおよびノードアフィニティに指定できるキーは限られており、今回はそのうちの
topology.kubernetes.io/zoneを使いました。詳細は https://cloud.google.com/kubernetes-engine/docs/concepts/autopilot-overview#node_selectors_and_node_affinity をご確認ください。↩