こんにちは。CTOの河内です。
多くのプロジェクトがスタート時はそうである通り、我々のプロジェクトもAPI仕様がありませんでした。 最初は規模が小さく問題として認識されていなかったのですが、規模が大きくなり、また開発者の入れ替わりを経験するごとに、「この API って何返してくるの?」という問いに答えられる人が段々といなくなってきました。 「ソースが仕様だ」とサーバの実装を読めばもちろん答えられるのですが、ソースコードを読み解く時間がかかるため効率的ではありません。 また、サーバ実装が唯一の情報源となるため、ロジックが何かおかしいと感じても、それが仕様なのかバグなのか判断できない状態でした。
API仕様を先に定義し、通信上の疑問にはAPI仕様で答えられるようにしたかったのです。 これは一般的な課題で、日本CTO協会が2019年12月に公開した DX Criteria DX Criteria では API 駆動開発として触れられています。 「なぜ、重要か。」に書かれている以下の文章は、我々が実現したかったことを言い表しています。
ネットワーク経由のAPIを基準にシステムを開発することで、他のシステムと連携しやすくなります。 またシステムがレガシー化した際に交換したり、改善したりといった手が打ちやすいものになります。 人が使う見た目の作りだけでなく、エンジニアにとっての作りが質を生み出します。
我々のシステムで対象となる API は REST ベースです。 REST ベースの API を記述する仕様記述フォーマットは OpenAPI*1、API Blueprint、RAMLなどいくつかあります *2。 この中では対応しているツールが多く、インターネット上の情報が豊富な OpenAPI を試すことにしました。
OpenAPI の仕様は YAML か JSON で書きます。 JSON はコメントが書けないので YAML のほうが便利です。 単純な API を OpenAPI で記述した例を次に示します。
openapi: 3.0.0 info: title: User API example version: 1.0.0 paths: /user: get: responses: '200': description: get user content: application/json: schema: description: response required: - id - name properties: id: type: string name: type: string age: type: number
我々も最初は OpenAPI でAPI仕様を書き始めたのですが、すぐに問題に気付きました。
まず行数が長くなります。
/user を GET すると id、 name、 age(ageはオプション) を返すという API を記述するのに、上の例では20行以上必要としています。
我々のAPI記述もすぐに縦に伸びていき、一部をカバーしただけで数百行に達しました。
またデータ型で必須・オプションの表現(required)とフィールドの宣言が離れているため、可読性が悪くミスが起きやすいという課題も発見しました。
大きなデータ型になると required が画面外に出てしまうこともあり、変更を忘れてしまったり、フィールド名が合っていない状態になることがありました。
これらの課題を解決するために OpenAPI を簡潔にかける DSL を作ろう!と思い立ちました。 OpenAPI の全機能を網羅しようとすると複雑度が一気に上るので、まずは我々のプロジェクトで使っている機能、我々が記述したい内容に絞って DSL を作りました。 次に例を示します。
info {
version "1.0.0"
title "User API example"
}
endpoint getUser {
GET /user
summary "get user"
response 200 {
body {
id: String
name: String
age?: Int32
}
}
}
まず24行から15行へと短くなりました。 実際に我々のAPIを記述したところ、OpenAPI から DSL にすることでおおよそ半分の行数になっています。 また必須・オプショナルを、フィールドの宣言と同じ行に書くことでミスしにくくしました。
DSL は scala-parser-combinators でパースし、抽象構文木(AST)を構築しました。 DSL に問題があったときに、OpenAPI に戻って保守が継続できるように、AST から OpenAPI 仕様に変換して出力できるようにしました。 また AST からサーバ側、クライアント側のコード生成するようにしました。 仕様から通信部のコードを生成することで、手間を削減するとともに実装時のミスを大きく減らせます。
プロジェクトへの導入が進み、複数の人が DSL を読み書きするようになりました。 プロダクティブにAPI仕様を記述できるようになり一安心していたところ、「エディタのサポートがほしい」という声が一部のメンバーから聞こえてくるようになりました。 普段、IDE やエディタの便利機能に助けられながら仕事をしているので、エディタサポートの利点は十分に理解できます。
Language Server Protocol (LSP) とは
さて、エディタをサポートするといってもいったいどのエディタをサポートすればよいのでしょうか? プログラマー用のエディタと言えば Emacs 派と Vi 派の印象が強いですが、 Visual Studio Code などの後発エディタや、IntelliJ IDEA のような IDE も人気があります。 人によってエディタの好みはさまざまですが、言語製作者としてはできるだけ多くのエディタをサポートしたいものです。
今回は複数のエディタに対応できるように Language Server Protocol (以下 LSP) を採用することにしました。 旧来はエディタごとに言語サポートを作成していました。 そのため、ある程度共通した機能セットを作成するために重複した実装がエディタごとに作成することになります。 LSP は重複実装の解消を狙ったプロトコルです。 共通部を Language Server として切り離すことで、一度だけ実装すれば良いようにします。 Language Server とエディタ間の通信仕様を定めたのが LSP です。
TypeScript、Scala、Goなど、すでに多くのプログラミング言語で Language Server が実装されていることから、LSP の狙いは開発者の心をとらえることに成功しているものと思われます。 サポートされる言語はこれからも拡大していくのではないでしょうか。
LSP は JSON-RPC を使っています。 JSON-RPC は JSON を用いて RPC するためのシンプルなフォーマットで、トランスポート層についての縛りはありません。 実際、TCP で接続を受け付けるように実装もできますし、標準入出力を使って実装することもできます。 エディタから子プロセスを起動して標準入出力を使うようにすればポート番号が重複することなどを考えなくて良いのはひとつの利点かもしれません。
JSON-RPC は JSON なのでヒューマンリーダブル、と言いたいところですが、実際のところは大量に通信が発生するため、生の JSON では理解が難しいことがあります。 LSP のサイトで利用できる LSP Inspector というツールを利用すると、リクエストとレスポンスを対応付けたり、特定種類の通信に限定して表示したりできるので、理解がはかどります。
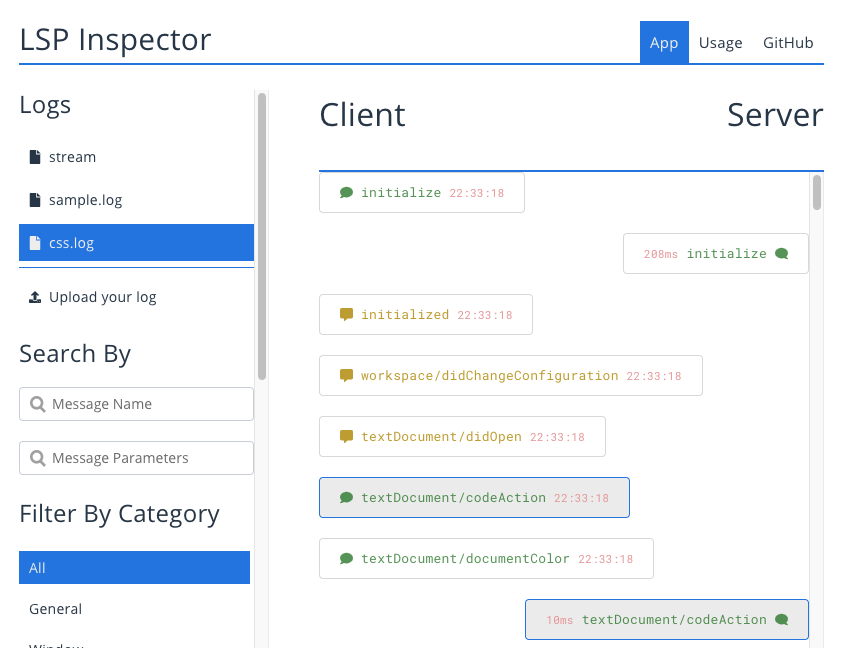
Eclipse LSP4J を用いた Language Server
Language Server の実装には、すでに Scala で実装していた DSL の parser を利用しました。 JVM 上の LSP 実装としては Eclipse LSP4J があるので、利用することにしました。 プロトコルをゼロから実装しなくても良いのは助かりますね。 ちなみに Scala 3 こと Dotty の Language Server でも LSP4J が利用されています。
初期化処理
LSP4J での Language Server の典型的な起動シーケンスは次のようになります。
val launcher = LSPLauncher.createServerLauncher(server, in, out) val client = launcher.getRemoteProxy server.connect(client)
ここでinは Language Server への入力、outは Language Server からの出力です。
標準入出力を使う場合は、それぞれ System.in、System.out が使えます。
ネットワーク経由で I/O する場合は ServerSocket#accept() して得られた Socket から getInputStream()、getOutputStream() すれば良いでしょう。
server は org.eclipse.lsp4j.services.LanguageServer と org.eclipse.lsp4j.services.LanguageClientAware の両インタフェースを実装したインスタンスを渡します。
LanguageServerには、エディタからのリクエストに応答する際に呼び出されるメソッドが宣言されています。
一方でエディタからのリクエストなしに、Languge Server から通知するユースケースもあります。
その際に利用するのが LanguageClientAware です。
続いて、LSP の初期化シーケンスを実装します。 初期化シーケンスは次のように進行します。
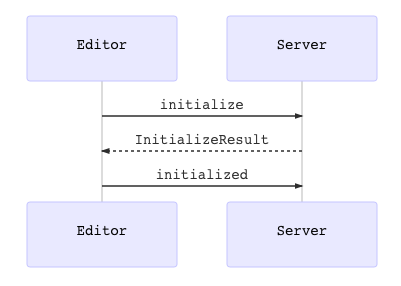
エディタから initialize リクエストが来たら、 InitializedResult を返します。
InitializedResult の中には Server の capability を明示します。
initialize の受信処理は LanguageServer#initialize() を実装します。
override def initialize(params: InitializeParams): CompletableFuture[InitializeResult] = { val capabilities = new ServerCapabilities() // 型定義へのジャンプ機能があることを明示 capabilities.setTypeDefinitionProvider(true) // 他にもできることがあれば capabilities に明示する CompletableFuture.completedFuture( new InitializeResult(capabilities)) }
initialize リクエスト・レスポンスが終わると、エディタは initialized を送ります。 initialized が来たら、ここからは Server からエディタに対して、通知を発行して良いという印です。
TextDocumentService
ファイルを開く、変更する、閉じるなどのイベントはtextDocument/didOpenといったメッセージで定義されています。
これらのメッセージのハンドラを定義しているのがorg.eclipse.lsp4j.services.TextDocumentServiceです。
LanguageServer#getTextDocumentService() で自身で実装したTextDocumentServiceを返します。
今回はファイルを開かれた、あるいは変更されたタイミングで、DSL のパースを行い、エラーがあれば箇所を特定しました。
特定したエラーはLanguageClientAware#connect()経由で取得したLanguageClientのpublishDiagnostics()でエディタに通知します。
また定義へのジャンプなどもTextDocumentServiceにハンドラが宣言されているので、実装することで機能を追加できます。
機能実装を追加した際にはinitialize時の capability への追加を忘れないようにしましょう。
こうして実装した Language Server は sbt-assembly で一つの .jar ファイルにまとめ、ダウンロード可能な場所に配備しました。
vscode-languageclient を用いたクライアント
Language Server が実装できたら次はエディタ側です。 LSPを使えばエディタ側の実装は一切不要、そう思っていた時期が私にもありましたが、そんなことはありませんでした。 定義ジャンプやエラー診断などの機能は Server 側で行うので不要なのですが、Server を起動する、特定の拡張子が来たときに拡張機能を有効にするなどといったクライアント側の機能実装が必要です。 今回は Visual Studio Code でのクライアントを実装しました。
Visual Studio Code の Language Server を用いた拡張機能は Language Server Extension Guide にわかりやすく書かれたドキュメントがあります。
ドキュメント中から参照されているシンプルなLSP拡張機能のサンプル実装 を参考にすることで、比較的容易に拡張機能を作成できました。
TypeScript で記述されているため、型の保護もありコードの変更もスムーズです。
クライアントがvscode-languageclientという npm package にまとまっており、拡張機能の実装は基本的に、自身の Language Server を起動するようにこの npm モジュールを呼び出すだけです。
拡張機能を有効にする拡張子を設定
まず mydsl という言語を追加し、.mdslという拡張子をこの言語に紐付けます。
そのためには package.json に次のように記述します。
"contributes": { "languages": [ { "id": "mydsl", "extensions": [ ".mdsl" ] } ],
また、mydsl言語を使うときに拡張機能を有効にするには、同じく package.json に次のように記述します。
"activationEvents": [ "onLanguage:mydsl" ],
こうすることで.mdslファイルを開いた際に拡張機能が有効になるので、有効になったタイミングで Language Server を起動し、vscode-languageclientから接続します。
export function activate(context: ExtensionContext) { // ここで Language Server のダウンロードをする(初回のみ) let serverOptions: ServerOptions = { command: "/path/to/language-server" }; let clientOptions: LanguageClientOptions = { documentSelector: [{ scheme: 'file', language: 'mydsl' }] }; client = new LanguageClient( 'myDSLServerExample', 'MyDSL Language Server', serverOptions, clientOptions ); client.start(); }
パッケージング
Visual Studio Code の拡張機能は一般的にマーケットプレイスで配布されています。
今回は内部向けの機能だったのでマーケットプレイス以外で配布したいというニーズがありました。
これは、vsceコマンドで .vsix ファイルを作成し、配布することで達成できます*3。
$ npx vsce package
このとき、package.json の publisher がサンプルと同じvscode-samplesのままだとエラーになるので、適当な名前に入れ替えます。
できあがった.vsixファイルはcodeコマンドでインストールできます。
$ code --install-extension mydsl-1.0.0.vsix
これで 最低限の Language Server と Visual Studio Code の拡張機能が動作するようになりました。 次の図はパース時に発生したエラーをエディタ上で表示している例です。
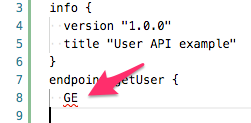
エラー表示の改善
LSP で通信しながらエラーの表示ができるようになりましたが、エディタの拡張として使ってみると scala-parser-combinators で書いたパーサに気になる点が出てきました。
今まで気になっていなかったところが気になるようになったのは、単純にエラーチェックの回数が増えたことと、書きかけの不完全な状態でチェックすることが増えたという2つの利用形態の変化が影響していると考えています。
過度なバックトラックの抑制
途中で文法に違反する箇所が混じっていると、エラーが表示されてほしい箇所より手前の箇所で end of input expected というエラーが表示されていました。
# ↓ 実際には先頭で end of input exptected
endpoint getUser {
GET /user
response
# ↑ 本当はここでエラーになってほしい
}
今回 DSL のパーサはscala.util.parsing.combinator.RegexParsersを継承して実装しており、パースにはparseAll()を使用していました。
parseAll()はパースを試みた後に、カーソルポジションが入力の最後に位置しない限り end of input expected というエラーになります。
我々の DSL ではトップレベル要素が endpoint を含め数種類あります。
文法エラーがトップレベル要素の途中にある場合、そのトップレベル要素には合致せず、バックトラックして次のトップレベル要素としてパースを試みていました。
結果として、合致するトップレベル要素が存在しないため、トップレベル要素の先頭でカーソル位置が止まった状態で終了するため、上述のエラーが出ていました。
scala-parser-combinators にはバックトラックをしないコンビネータがあります。
これらを適切に使うことでバックトラックを抑制し、適切な位置にエラーを出せるようになりました。
バックトラックをしないコンビネータは通常のコンビネータの後ろに!がついています。
たとえば endpoint というトップレベル要素のパーサの書き出しは~>を使って次のようになっていました。
"endpoint" ~> ident
これを~>!を使うことでバックトラックを抑制し、適切な位置にエラーを出すようにしました。
"endpoint" ~>! ident
適切な Failure メッセージの設定
たとえば HTTP のステータスコードを入力する箇所では次のように正規表現でパースしていました。
lazy val statusCode: Parser[Int] = """\d{3}""".r ^^ (i => i.toInt)
上記の実装に対してパースできない入力を与えると string matching regex '\d{3\' expected but 'X' found} というエラーになります。
これは分かりづらいですね。
パース失敗時のメッセージは withFailureMessage() で指定できるので、ユーザーにとって理解しやすいメッセージを指定します。
lazy val statusCode: Parser[Int] = ("""\d{3}""".r ^^ (i => i.toInt)) .withFailureMessage("Expected status code. ex. 200")
正規表現だけではなく parser1 | parser2 | parser3 といった選択肢もエラーメッセージが分かりにくくなります。
いずれにも合致しないときに、最後に試行した parser3 のエラーメッセージが表示されるからです。
(parser1 | parser2 | parser3).withFailureMessage(...) など、わかりやすいエラーメッセージを指定したほうが良いでしょう。
最初のエラーしか出せない
エディタやIDEでプログラムしていると、途中に文法上パースできない箇所があってもそこで止まらず、その下もチェックしてくれることが多いと思います。
しかし今回実装したパーサでは最初のエラーしか出せません。
パース結果を保持するデータ構造が最初のエラーが起きた場所しか保持しないことから、scala-parser-combinators を使う前提では解決できないことがわかります。
Visual Studio Code のドキュメントでは Error Tolerant Parser for Language Server というトピックに記載があります。 PHPのパーサ実装を例にして設計を説明しています。 興味のある方は参照してみてください。
最初のエラーが表示されるだけでも助けにはなるので、今回はパーサの再設計は見送りました。
まとめ
本章では API 仕様を記述するための独自外部 DSL を作成するに至ったきっかけと、そのエディタサポートの LSP をつかった実装について触れました。 DSLの文法やツールセットのコードは小さなものですが、記述のしやすさや、記述される仕様の質を大きく上げられたのではないかと感じています。 今回は Visual Studio Code だけに対応しましたが、機会があればほかのエディタにもサポートを広げたいと思っています。
*1:以前は Swagger と呼ばれていた。
*2:ゼロからシステムを構築する場合は grpc-web も有力な選択肢になりそうですが、既存システムの仕様を記述するには向かないため選択肢から外しました。
*3:Visual Studio Code の Publishing Extensions を参照。