こんにちは、渡部です。
これは先日行われたAWS勉強会で話した内容をまとめた記事です。
私は普段データチームとして広告データやレポートデータが格納してあるデータウェアハウスの開発・運用・保守等を行なっています。
その業務の中で使用している、データ処理に関するサービスのAWS GlueとAmazon Athenaについて紹介しました。
AWS Glue
概要

Glueは一言で表すならサーバーレスのETLサービスです。
ETLとは「Extract(抽出)・Transform(変換)・Load(格納)」というデータに関する一連の処理のことを指します。
Glueを使うことでS3やRDSにあるデータを抽出・変換して、S3やRDSなどに再び格納することができます。
使用例
データチームでGlueをどう使用しているのかを説明します。
広告媒体のAPIから取ってきてS3に格納してあるjsonデータに対してGlueで処理を行います。
変換処理の内容としては、jsonをバラして構造化データにしたり、カラム名を変更したりといったことを行なっています。
変換後のデータをデータウェアハウスに格納しています。
以前はデータの変換をEmbulk独自のパーサーで行なっていましたが、Glue利用に変更したことにより処理時間の短縮にも繋がりました。

Amazon Athena
概要

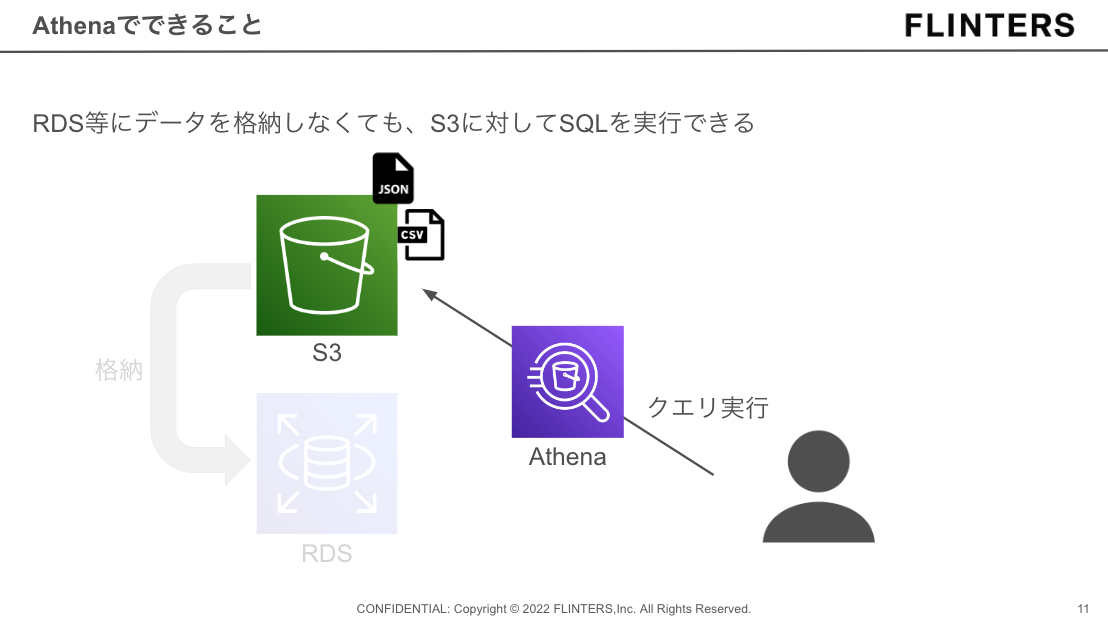
Athenaは、S3内のデータに対してSQLを実行できるサービスです。
通常S3にあるデータに対してSQLを実行したい時は一旦RDS等にデータを移して、RDSに対してSQLを実行するのが一般的かと思います。
しかしAthenaを使うことで、RDSを用意する必要なくS3に対してSQLを実行できるようになります。
使用例
データチームでの使用例としては、まずS3に格納した広告データに対してクエリを実行し、広告タイプというものを判別します。
その後判別結果をもとに、データウェアハウス上の別々のテーブルにデータを格納します。
広告タイプを判別するために新たにストレージを用意する必要がないため、ストレージコストや手間の削減に繋がります。

まとめ
簡単にではありますが、データ処理に関するAWS GlueとAmazon Athenaの紹介をしました。
この記事では深いところまでは言及しないですが、これらのサービスには今回紹介した以外にもさまざまな機能があるので、興味がある方は詳しく調べてみることをお勧めします。