こんにちは、データマネジメント部でデータエンジニアをしている井山です。
この記事は10周年記念として133日間ブログを書き続けるチャレンジの15日目の投稿になります。
今回は、現在FLINTERSデータチームで行っているデータ基盤移行PRJ(実施中)についてのお話をしたいと思います。
はじめに
データ基盤の現状
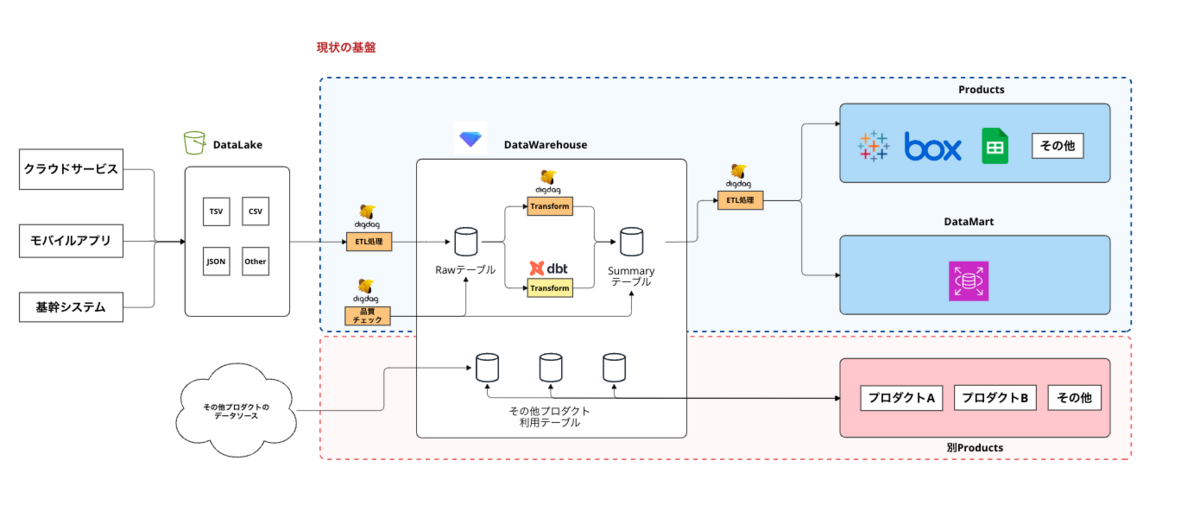
データチームでは、Treasure Dataを中心としたデータ基盤を管理・運用をしています。
基本的な構成としては下記の様に、各種データソースがあり、データレイクとしてS3にデータを格納しています。
そこからDigdag・Embulkなどを用いて、DWH(TreasureData)へデータを格納し、そこから各種プロダクトへ利用するような形となっています。
※ 昔ながらのETL環境といった形
移行の背景
長年この環境でやってきていたのですが...
- 利用者・プロダクトが年々増加
- 重たいクエリが流れ出す
- データ量の増加
- etc...
が発生し、DWH側のリソース問題が散見されるようになってきました。
発生していた問題点
- 利用が進んだことで契約リソースに見合わない基盤利用の仕方が散見される状態
- 特定時間のスパイク・特定のクエリが極端に重く(お行儀悪いクエリ等)、リソースを圧迫
- 結果としてDWH全体が低速モードに入り全体が遅延
- 遅延した結果、キューにどんどんクエリが投げ込まれ、さらに悪化、キューの最大値に達してしまい、それを超えたクエリがエラーで消える事態が発生
- データ量が年々増加し、契約レコード上限に抵触しかける事態に
- 関連するプロダクト全体に影響を与える場面も何度か発生
暫定的な対策
- クエリの見直し・クエリ警察実施(よくないクエリをしょっぴく)
- 監視機能の強化(APIから情報取得し独自の監視ダッシュボードを構築)
- ジョブから監視のためのメタデータを自前で取得する処理を作成
- 契約形態の見直し(並列数を上げる、CPUユニットの強化)※契約コスト増
- データライフサイクルの導入(2年経過したデータは自動削除)
などなど実施した結果、現在は落ち着いているものの
TreasureDataの技術特性や料金体系にはマッチしないようなユースケースも散見されるようになり...、基盤のリソース状況に合わせてデータ利用を行うは限界...
諸々の問題点を解決するために。

移管対応でやったこと等
※ 今回の移管PRJは基盤をSnowflakeに載せ替えることを第一としており、Snowflakeライクなアーキテクチャや関連するサービスの見直しなどは大きくは行わない前提でやっています。
やったこと
- 過去データの投入
- TreasureData -> Snowflake の Connector は存在しているものの、データの規模が大きい場合はかなり負荷が大きいため、過去データの投入はS3に出力したファイルから一括で取り込む形で対応
- WFの修正(Digdag)
- 既存のプロダクトは常時動いている状況なので、TreasureDataとSnowflakeは並列稼働させつつ、各種データフローをTD、SFどちらにもデータを出力するような形で対応
- 移管に伴い、Digdag WF + SQL で実装していたデータ品質チェックを dbt のテストを用いたチェック処理に移管
- DBやユーザ・権限周りの構成管理をTerraformで実施するように変更(Terraformの Snowflake Provider を利用)
- 一部プロダクトでDHWを参照する関係上、データチームで権限管理していた部分を Snowflake の Datashring を用いて、切り出し。権限管理を別チーム内で完結できるように
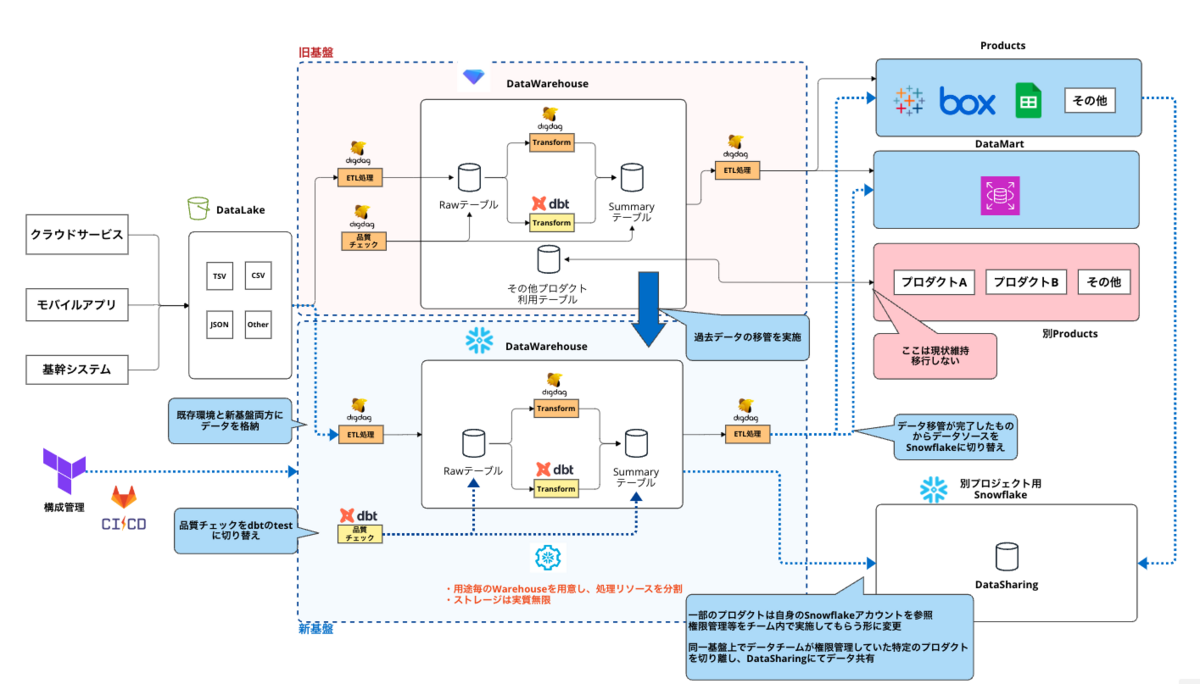
現在の構成は上記のような形で、徐々にデータを移管しつつ、TreasureData・Snowflakeを並行稼働している状態です。
媒体データの定期格納処理はおおよそ移管が完了し、徐々にデータ利用側のプロダクトがSnowflake利用に切り替わりつつある状況になってきました。
まとめ
Snowflakeにしてよかった点
リソース問題はほぼ解消
処理単位で、Warehouse、サイズを切り分けることができ、以前発生していたような、特定の重いクエリが他の処理に影響を与えることは無くなった。
格納できるデータ量も無制限なのでライフサイクルも廃止(全期間のデータを格納できる)
データの格納は実質無制限なので、全期間のデータを格納できるようになり、S3に退避させていたデータもDWH上に格納し、参照できるような環境に。
コスト的な部分でのメリット
基本的なコストはWHの利用料+ストレージとなりますので、動いていない時間帯はコストはかからず、全体費用としては以前より良くなる見込み。
DWHの構成管理ができるように(一部例外はあるが)
一部例外はあるものの、DB、Schema、ユーザーアカウント、権限周りなどをコード管理(Terraform)できる様になり、運用作業(権限付与や新規DB構築)など、以前は手作業だった部分が、コードレビュー、CI/CDを通して実施できるように。
メタデータ関連がかなり強力
関連する情報をSnowflakeが用意してくれているViewからかなり詳細に取れる(Viewの期間は決まっているので必要なものは永続化)ので、それらを利用しての、各種データ監視ダッシュボードの構築などを行える状況になりました。
例)プロダクト毎、WH単位でのコストの表示
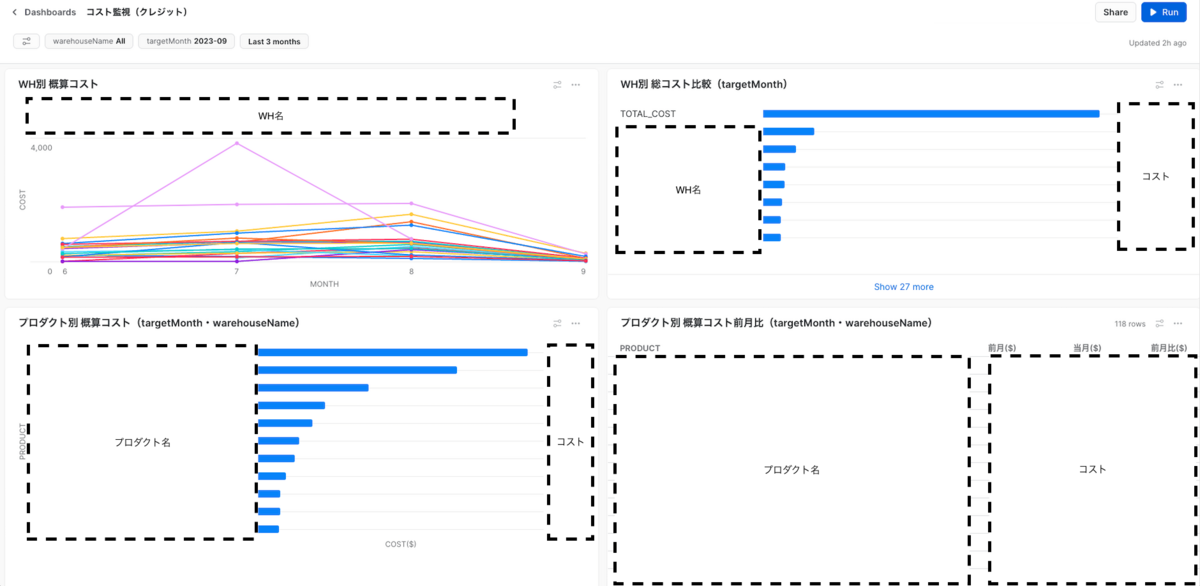
例)WH単位での処理状況・キュー待ちの状況

副次的にいらない・使っていないデータソースとかを排除する動きが活発に
こちらは副産物ではありますが、移管作業に伴って使っていないデータソースや後続のプロダクトやらがちらほら見られ、費用対効果あってないよね?という話ができ、それらについてはクローズしていくような動きが出てきました。
コスト面の可視化をしたことで費用対効果をユーザ側でも見ることができ、コスト意識が自然と出てきたことは良いことだったなと思います。
困ったこと・苦戦したこと
Digdag WFからのSnowflake接続
これまで我々の環境はTreasureDataがメインのDWHであったことから、同じくTreasureData社が提供しているWFツールであるDigdagをメインに採用していました。
DigdagにはSnowflakeに対して直接接続してクエリを実行する為のOperatorがないため、こちらは自社内でPluginを自作することとなりました。
WFツール自体の変更も考えたのですが、既存処理の移管作業がかなり重たくなってしまうため、一旦はDigdagのまま移管は進めることとなりました。
TreasureData時に利用していたIntegrations機能とのFit & Gap
Snowflakeを比較するとImport/ExportについてはTreasureDataの方がオプションが多くFit&Gapがかなり大変に...
TreasureData は Import/Export 共にTreasureData側で用意されているIntegrationがめちゃくちゃありとても優秀です。
https://www.treasuredata.com/data-integrations/
全てのIntegrationを利用していた訳ではないですが、それでも一部の用途はすぐに対応することは難しいという判断を下すこととなりました。 (反面切り捨てていいデータソースとか利用用途を炙り出せたのである意味良かった部分でもあります)
TreasureDataの独自関数→Snowflakeだとどうなるの問題
TreasureData の環境では、TD_ から始まる、TreasureDataの独自関数が用意されており、それらにかなり依存している形でした。
その為、単純に実行するSQLをそのままSnowflakeに持って行ったとしても簡単には実行できない状況になっていました。
幸い我々のTreasureDataの利用環境では、各種実行ログを別途蓄積しており、利用している独自関数を全て洗い出すことは可能だったので、書き換えが必要な関数を一覧化し、それぞれどのように書き換える必要性があるかを調査して対応を行いました。
今後やっていきたいこと
現時点ではあくまでのTreasureDataからSnowflakeへ基盤を移し替えを始めたのみで、これまでの技術的負債などは残っている部分もあります。
具体では以下のようなことをやりたいなぁと個人的には考えてはいるものの、まだまだ手が出しきれていない状況です。
- データアーキテクチャの見直し(今回のプロジェクトはあくまでも初回でデータ構造などは基本そのまま移行)
- データ基盤の構成、フローをもっとシンプルにしたい(ETL→ELTへの変更やWF関連の最適化)
- データ層を綺麗にしたい(Rawデータ層とかキュレーション層 etc...)
- データ品質チェック周りの拡充
- dbtのテスト機能を用いてこれまでSQL+Python+Digdagで実施していた部分を移管中(正確性、完全性、一貫性、一意性、整合性、適時性、有効性 etc...)
- dbtの Package関連 で結構これらを網羅してくれているので利用進める
- メタデータ関連の拡充
- データリネージやその他Snowflake側のメタデータを用いてなるべく不明な点(問い合わせ少なくなるような)がないような形でデータカタログなどを提供したい
足りていない部分やもっとこうした方が良い!といったことは今後の運用でも出てくるとは思うのでそれらに対応しながらより良いデータ基盤作りをしていきたいと考えています。
FLINTERSでは一緒に働く仲間を募集しています!興味のある方は是非以下より!