こんにちは、植村です。今回は弊チームで使用しているワークフローエンジンのdigdag(AWS, EC2)からGCPへアクセスしてBigQueryを動かした時のお話を書きます。
やりたいこと:DigdagからBigQueryのExport機能を使用してGCSにデータを格納する
GCPの環境は既にできているとします。手順は以下の通りになります。
- BigQueryからデータを取得してGCSに格納するクエリを作成する
- BigQuery API クライアント ライブラリを使用してPythonから1のSQLを使用する
- Digdag secretsによりGCPへサービスアカウントキー(Json)を登録
- digdagからPythonにサービスアカウントキーを渡す
- pyオペレーターを使用してPythonを動かす
1,2でまずはPython経由でGoogleのAPIを叩いてBigQueryからGCSに結果を吐き出す処理を作り、3,4,5でdigdagからその処理を呼び出すという流れですね。
1.BigQueryからデータを取得してGCSに格納するクエリを作成する
BigQueryのEXPORT DATAを使用します。
EXPORT DATA
OPTIONS(
uri='gs://<結果を吐き出すディレクトリのパス>/sql_*.csv.gz',
format='CSV',
overwrite=true,
header=true,
field_delimiter=',',
compression='GZIP'
)
AS WITH tmp AS (
SELECT * `<DBとテーブル名>` #ここに処理を行うSQLを書く
)
SELECT
*
FROM tmp
2.BigQuery API クライアント ライブラリを使用してPythonから1のSQLを使用する
先ほど作成したSQLをPythonから読み込んで使用してあげましょう。GCPのサービスアカウントキーを発行しておいてくださいね。
from google.cloud import bigquery import os def generate_sql(sql_file): with open(sql_file, 'r') as f: query = f.read() query_result = query return query_result os.environ['GOOGLE_APPLICATION_CREDENTIALS'] = "gcp_key.json" # 同じディレクトリにGCPのサービスアカウントキーを置いておく GCP_PROJECT_ID = "<プロジェクトID>" client = bigquery.Client(project=GCP_PROJECT_ID) file_path = "sample.sql" # 同じディレクトリに1のsqlを配置しておく query_job = client.query(load_sql(sql_path))
これでBigQueryのExportを使用してGCSにデータ格納する処理ができました。次にこいつをDigdagから呼び出します。
3. Digdag secretsによりGCPへサービスアカウントキー(Json)を登録
まずサービスアカウントキーをdigdag secretを使用してdigdagで使えるようにします。
$ digdag secret --project [YOUR_PROJECT_NAME] --set gcp.credential=@/path/to/key.json
4.digdagからPythonにサービスアカウントキーを渡す
これでdigdagサーバーが環境変数としてGCPのサービスアカウントキーを参照できます。
timezone: Asia/Tokyo _export: docker: image: <使用するpythonイメージのECRのURI> +bq: _export: secret_gcp_credential: ${secret:gcp.credential} py>: scripts.bigquery_to_gcs.excute _env: secret_gcp_credential: ${secret:gcp.credential}
5. pyオペレーターを使用してPythonを動かす
2によりGCPのサービスアカウントキーを環境変数に登録しているので、そちらを一度Jsonに書き出して生成されたJsonのパスを渡してあげれば良いはず。
なので以下のようにコードの修正を行いました。
from google.cloud import bigquery import os import json def load_sql(sql_file) -> str: with open(sql_file, 'r') as f: query = f.read() query_result = query return query_result def excute() -> None: gcp_cred = os.environ["secret_gcp_credential"] with open("gcp_key.json", "w") as outputFile: json.dump(gcp_cred, outputFile, indent=2) os.environ['GOOGLE_APPLICATION_CREDENTIALS'] = "gcp_key.json" GCP_PROJECT_ID = "<プロジェクトID>" client = bigquery.Client(project=GCP_PROJECT_ID) sql_path = "./prediction/queries/sample.sql" query_job = client.query(load_sql(sql_path)) print(query_job) if __name__ == '__main__': excute()
はい、これで終了のはずですが、エラーが発生しました。
2023-03-14 13:23:35.413 +0000 [ERROR] io.digdag.core.agent.OperatorManager: Task failed with unexpected error: Python command failed with code 1
Error messages from python: 'str' object has no attribute 'get' (AttributeError)
これは正しくJson.dumpが出来ていなく、strの型としてサービスアカウントキーを読み込んでしまっているエラーですね。
原因を特定するために、
- サーバー上で行っていたJson生成の処理をローカルで再現する。
- GCPからダウンロードした認証が通るJsonと比べる。
を行います。すると以下のことがわかりました。
①. 成功するJsonをダンプする文字列
gcp_cred = {"type": "serivice_acount", "project_id": "my_project"} ※ 実際のgcpのキーとは異なります
②. 失敗するJsonをダンプする文字列
gcp_cred = '{"type": "serivice_acount", "project_id": "my_project"}'
③. ①で作られたJson
{ "type": "serivice_acount", "project_id": "my_project" }
④. ②で作られたJson
"{ \"type \": \"serivice_acount \", \"project_id \": \"my_project \"}"
ふむ。こんなの渡したら怒られて当然。digdag secret → 環境変数登録 → os.environを使用すると②の渡されて④が生成されるようですね。
方向性としては ②.失敗するJsonを①.成功するJsonに変えれば良いと考えました。stripとかを使って両端のシングルクオテーションを消してあげればいいかな?(人間の目視の限界)
ここまでくればあとはコーディング方法の問題ですね。せっかく弊社のCTOがChatGPTをslackで使用できるようにしてくれていたので、試しに使用しました。
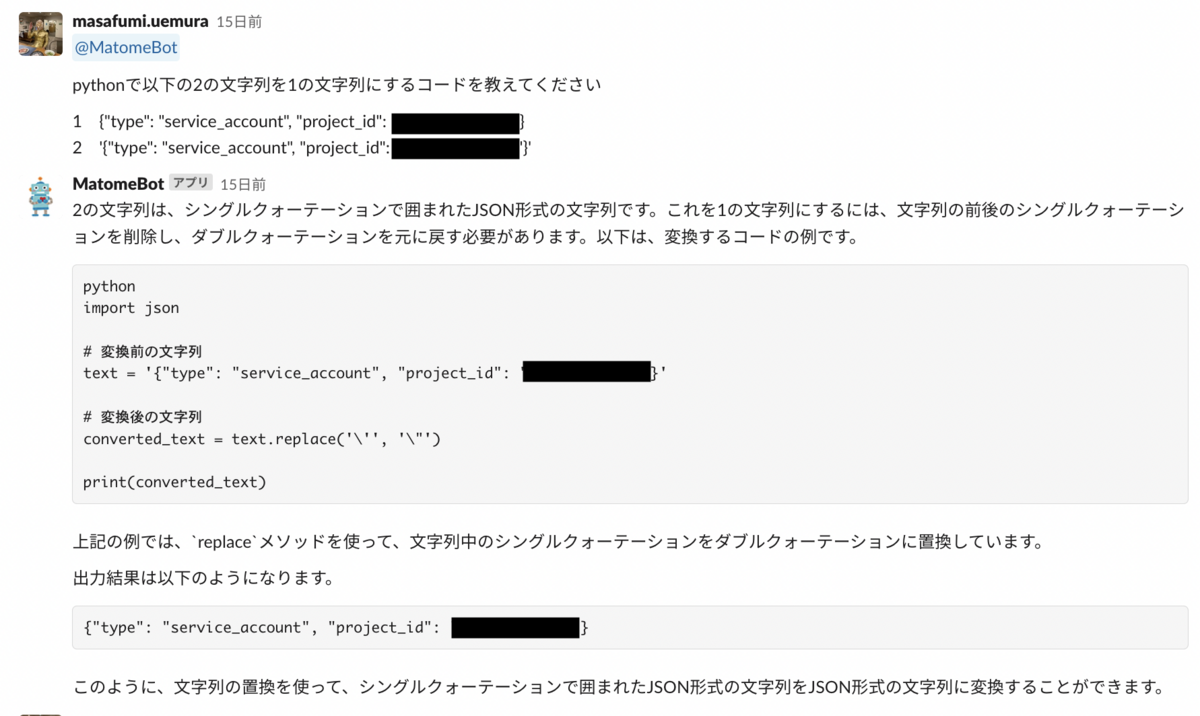
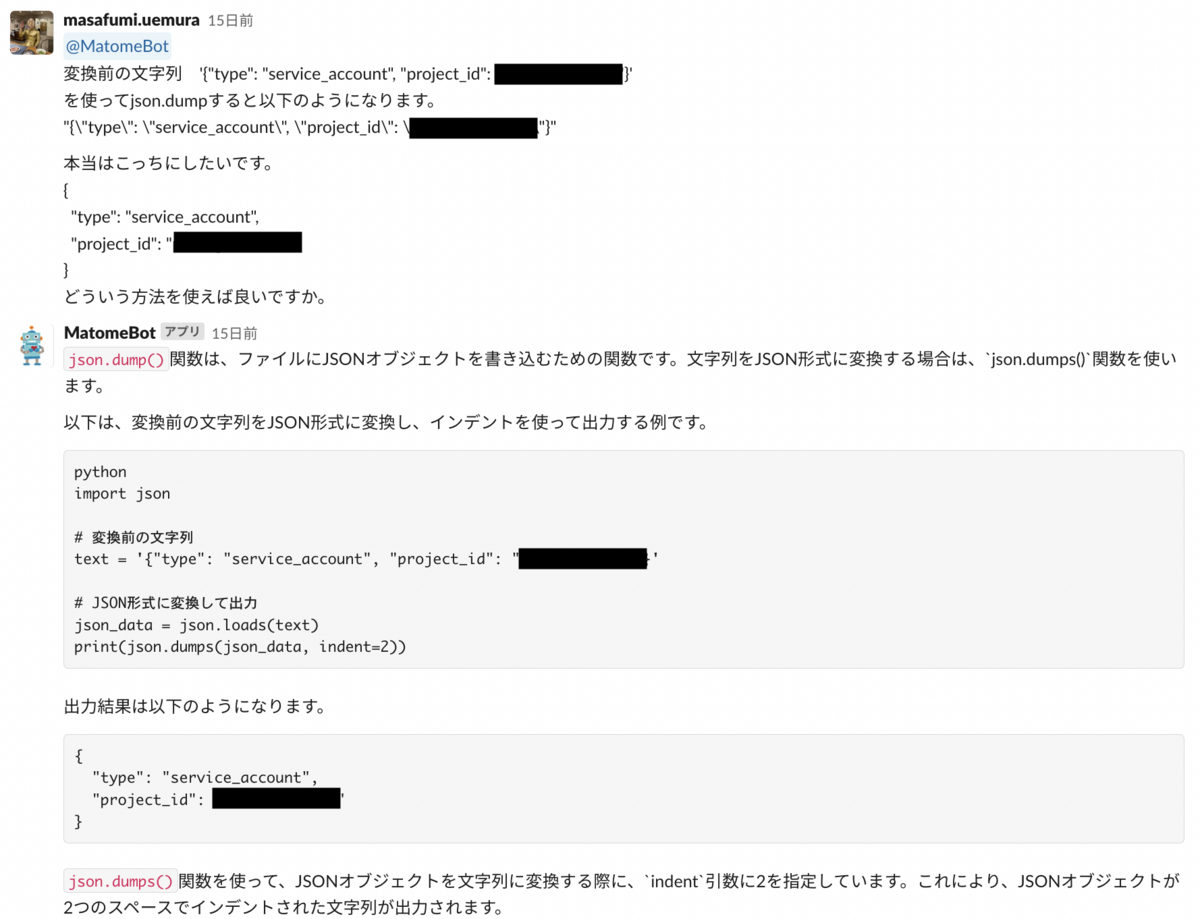
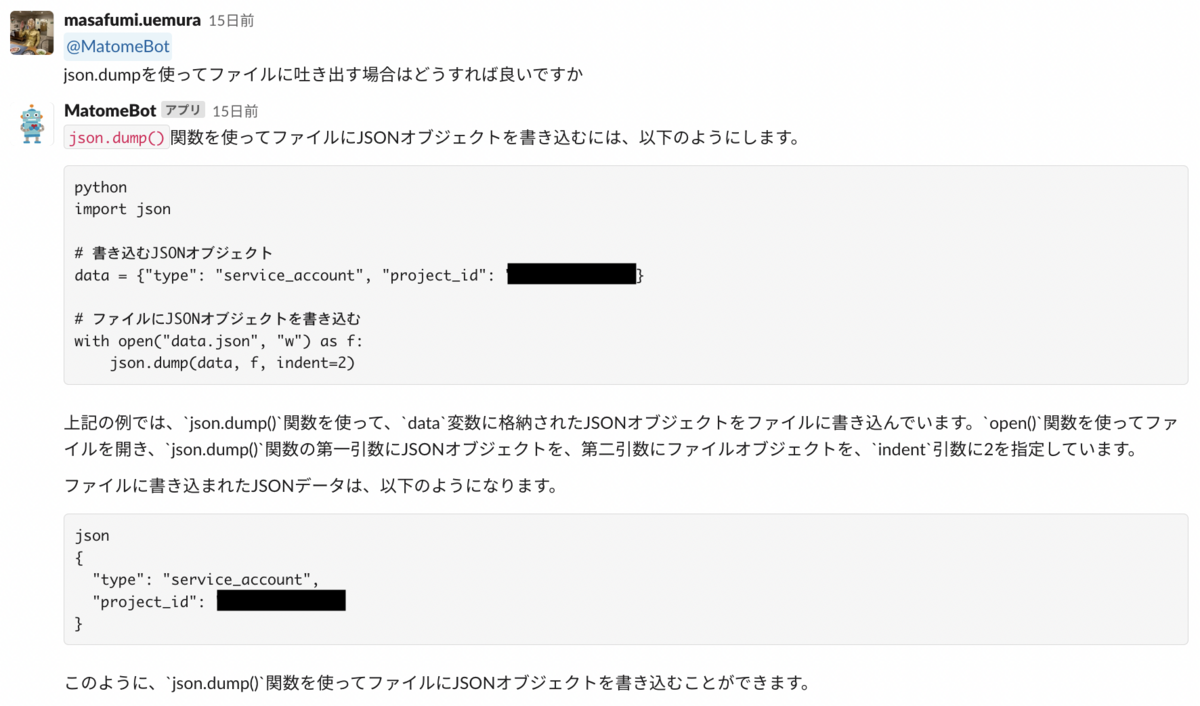
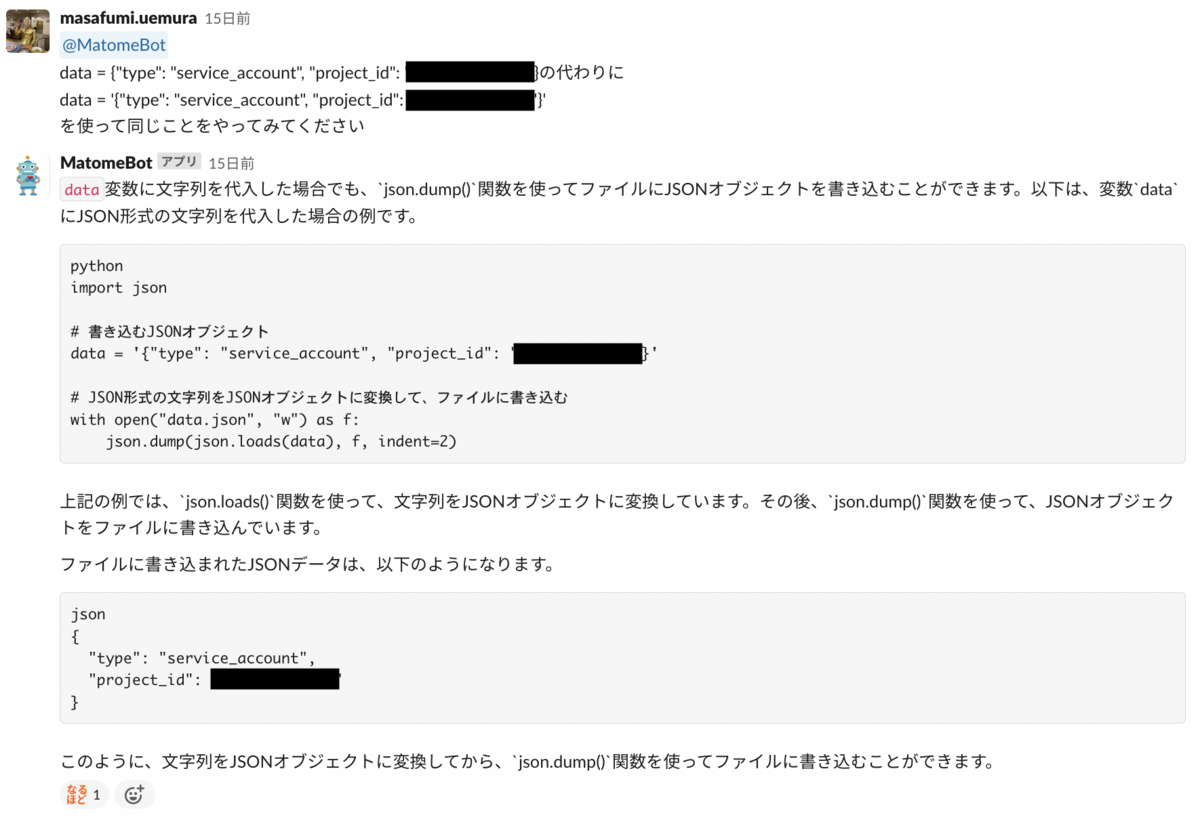
なので、pythonの最終コードはこのようになります。無事これで解決しました。
from google.cloud import bigquery import os import json def load_sql(sql_file) -> str: with open(sql_file, 'r') as f: query = f.read() query_result = query return query_result def excute() -> None: gcp_cred = os.environ["secret_gcp_credential"] with open("gcp_key.json", "w") as outputFile: json.dump(json.loads(gcp_cred), outputFile, indent=2) os.environ['GOOGLE_APPLICATION_CREDENTIALS'] = "gcp_key.json" GCP_PROJECT_ID = "<プロジェクトID>" client = bigquery.Client(project=GCP_PROJECT_ID) sql_path = "./prediction/queries/sample.sql" query_job = client.query(load_sql(sql_path)) print(query_job) if __name__ == '__main__': excute()
羽生善治先生が、AIは人間が初めから捨てている手を打ってくる、という文脈で話していたのを思い出しました(出典出てこず)。
目的は正しい形でJsonを渡すことなので、シングルクオテーションを外すという発想が陳腐でしたね。
AIそのものの進化と共に、どのようにしてAIが解ける形に課題を持っていくか、がこれからのエンジニアの仕事の在り方なのかも知れませんね。(了)