皆さま、明けましておめでとうございます!
株式会社FLINTERSのDataチームに所属しています、西垣です。
年明け三が日のど真ん中をいかがお過ごしでしょうか?
10周年記念ブログリレーの第116回目を担当させていただき、いよいよゴールが近付いてまいりました。
位置的には抑え投手(?)かと思われますので、安定感ありつつも、閲覧される方々にとって新鮮味のあるブログとなるように努めさせていただきました!
お手隙の際にでもご観覧いただけますと幸いです🙇♂️
プログの内容について
2022年、生成系AI技術が爆発的に成長し、利用頻度は一気に拡大したかと思います。私自身、コーディングの不明確な点やリファクタリングの観点からChatGPTを利用して業務に活用する機会も多く、利便性の高いツールであることは自明であり、エンジニアの方々もかなり扱い慣れている頃合いではないでしょうか?
ChatGPTが普及したタイミングが私の入社と同時期であり、生成系AIネイティブとして何か会社内に取り込めないかとの意欲もあり、OpenAIが提供するサービスをもうワンランク上で扱えるようにこちらのブログで情報共有させていただく次第となりました!
ブログの構成
全てを伝えきるにはブログでは少々短すぎるため、かなり省略気味ではあります💦
また順を追って技術共有ができればと思います!
今回の進行は以下となります。
- OpenAI APIとLangChainで長文データを扱う
- SQLDatabaseChainでSQL問い合わせツールの検証
OpenAI APIとLangChainで長文データを扱う
普段触れるChatGPTはチャット会話文の範囲内に埋め込まれた文脈を利用して回答を導くものです。しかし、プロンプトに埋め込むことのできるサイズは限定されており長い文章を扱うことが難しいという欠点をはらんでいます。
今回はLLM(Large Language Model)と連携ができるベクトルデータ構築によって長文を要約したり、それらを基に質疑応答可能な方法を実装してみたいと思います。もっと応用ができれば社内文書や、技術文書などをまとめるツールが作れるはずです!
LangChainとloader
LangChainはLLMと外部データ連携やLLMタスクの自動化のためのライブラリです。
詳細については公式ドキュメントを参照してください。
LangChainの基本はテキストデータからベクトルデータを生成することですが、実際の現場ではWeb、PDF、Wordなどテキスト以外の文書がほとんどです。これをloaderを使うことで様々な入力ソースからインデックスを作成することが可能となります。
各種loaderは公式ドキュメントを参照してください。
実践
開発はGoogle Colaboratoryで、Webから情報を取得しインデックス化を行いました。
※ OpenAIのAPI Keyは西垣個人のものを使用しています。
OpenAIへ接続
!pip install openai
import os os.environ['OPENAI_API_KEY']="<<自身のAPI Key>>"
ライブラリのインストールとインデックスの作成
!pip install langchain !pip install chromadb !pip install tiktoken !pip install unstructured !pip install pdf2image
これによりLangChainのデータローダーであるUnstructuredURLLoaderが使用可能となります。このローダーはURLを複数指定できる点がポイント高いです。
次はWikipediaから『夏目漱石』と『森鴎外』を読込インデックスDBとして作成します。
from langchain.text_splitter import CharacterTextSplitter, RecursiveCharacterTextSplitter from langchain.chat_models import ChatOpenAI from langchain.embeddings import OpenAIEmbeddings from langchain.vectorstores import Chroma from langchain.chains import RetrievalQA from langchain.document_loaders import UnstructuredURLLoader urls = [ 'https://ja.wikipedia.org/wiki/%E5%A4%8F%E7%9B%AE%E6%BC%B1%E7%9F%B3', 'https://ja.wikipedia.org/wiki/%E6%A3%AE%E9%B7%97%E5%A4%96' ] loader = UnstructuredURLLoader(urls = urls) documents = loader.load() text_splitter = RecursiveCharacterTextSplitter(chunk_size = 500, chunk_overlap = 0) texts = text_splitter.split_documents(documents) embeddings = OpenAIEmbeddings() db = Chroma.from_documents(texts, embeddings) retriever = db.as_retriever() qa = RetrievalQA.from_chain_type(llm = ChatOpenAI(model_name = 'gpt-3.5-turbo'), chain_type="stuff", retriever=retriever)
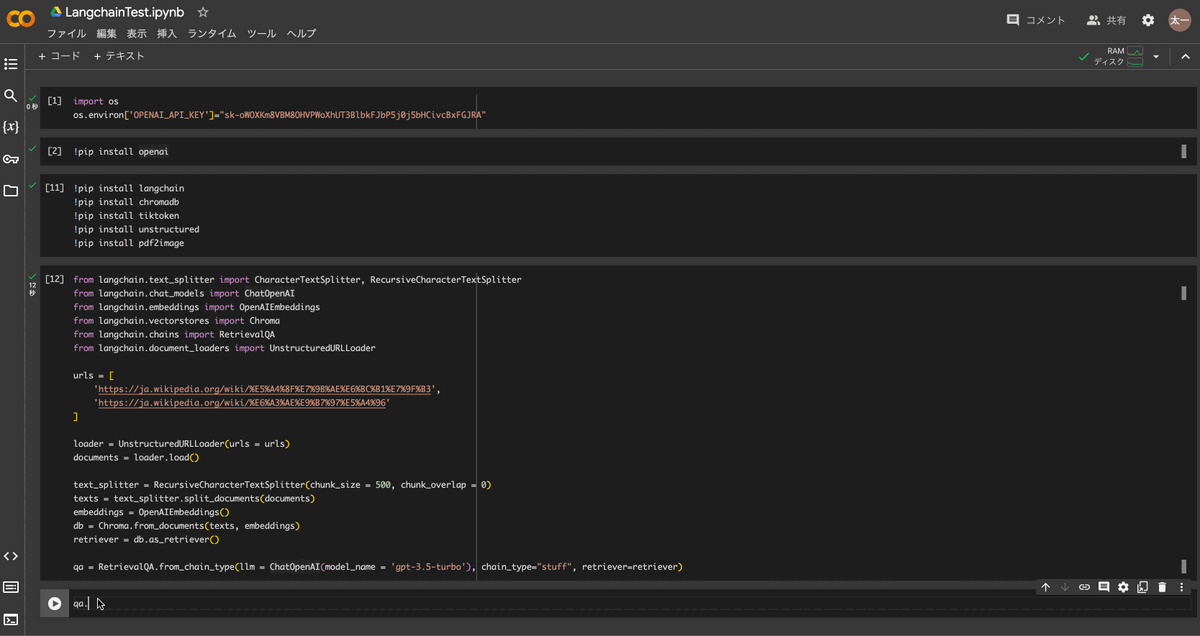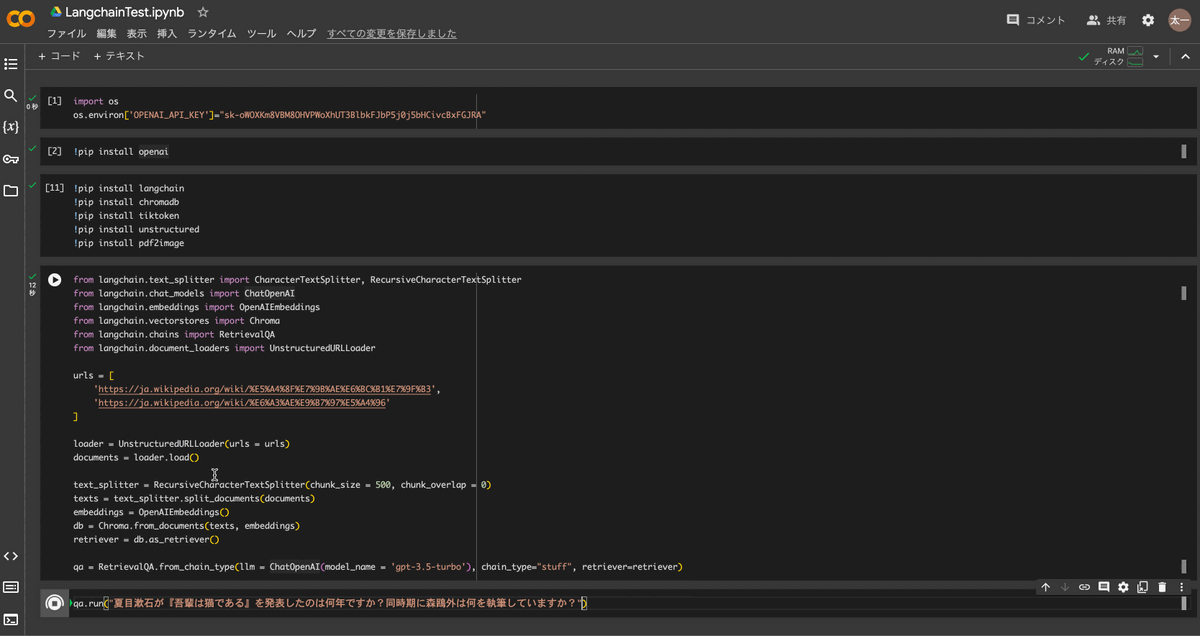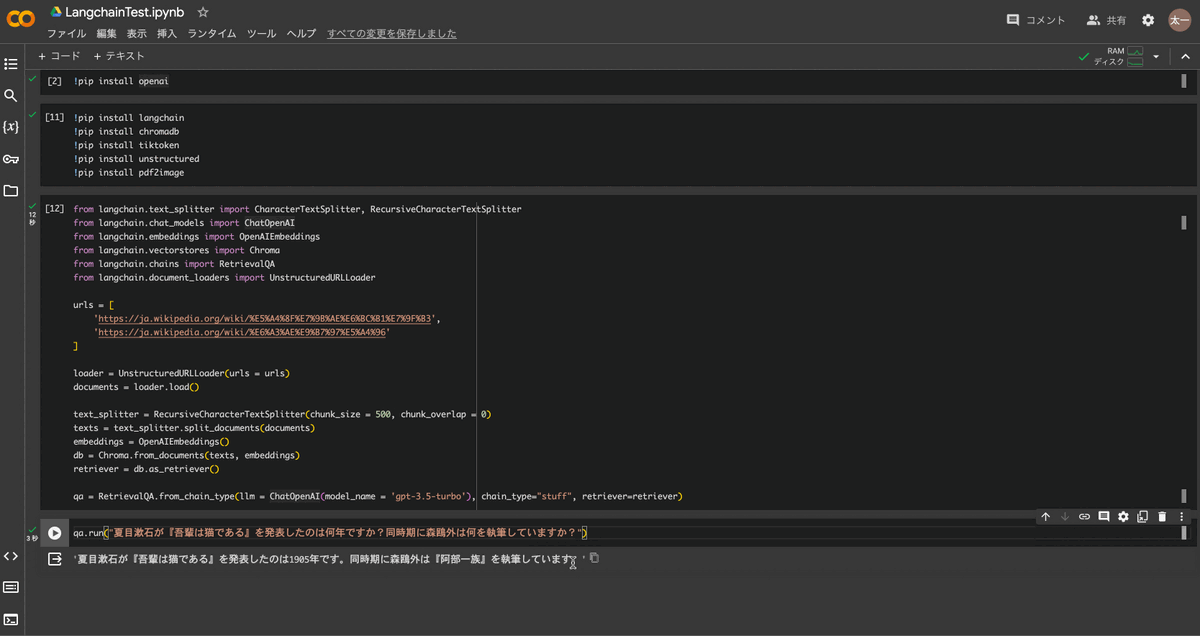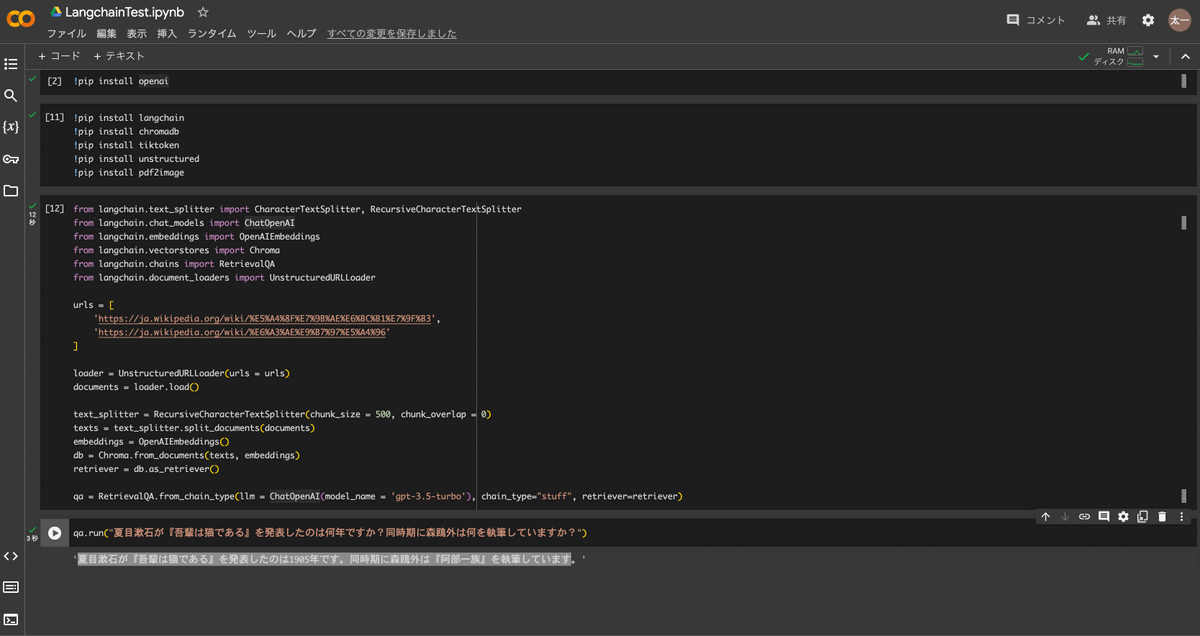
検索はqa.run("テキスト")によって以下のように実行されました。
SQLDatabaseChainでSQL問い合わせツールの検証
私はDataチームに所属しているため、DBへのアクセスは日常茶飯事です。ただ、確認したいことがある度に毎回SQLをたたくのが億劫になることもあり、作業効率化として何か自動化する手立てはないかと探っていた中でSQLDatabaseChainを使ったSQL問い合わせツールに糸口を感じ、簡易な設計を行ってみました。
DBの作成
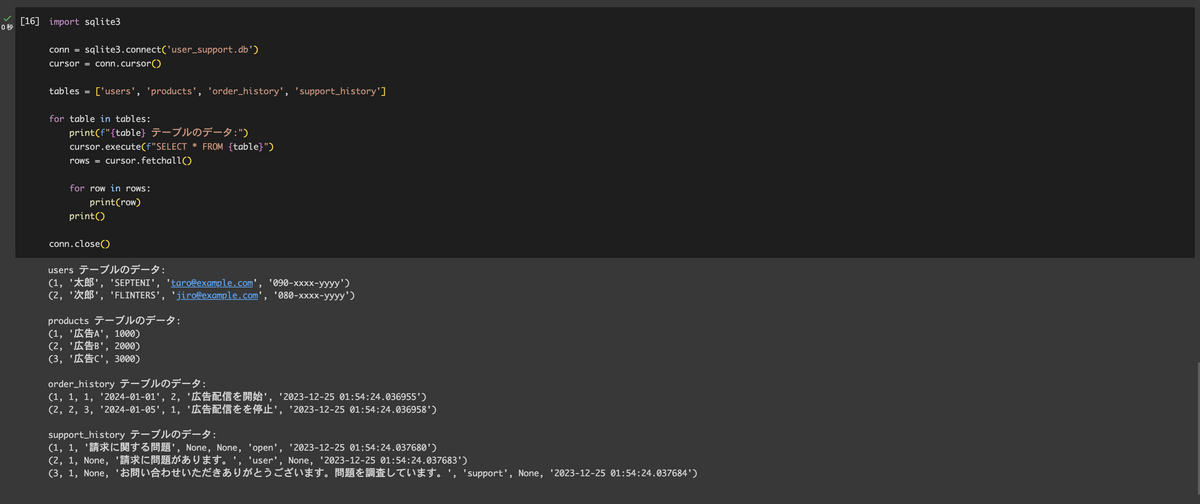
まず、下記のER図をもとにSQLDatabaseオブジェクトをsqliteで定義します。
※ DBの作成は少々長くなるため割愛します🙏

チャットボットの作成
作成するチャットボットは以下3点のタスクを追加します。
- ユーザーを特定する
- そのユーザーに関する情報の全てを取得する
- サポートを行う
① ユーザーを特定する
まずはライブラリの追加から行います。
!pip install -U langchain langchain_experimental
import json sql_uri = "sqlite:///user_support.db" db= SQLDatabase.from_uri(sql_uri) llm = ChatOpenAI(temperature=0.2) def find_user(user_text): template= \ """ ユーザテーブルのみを対象とします。次の要求文に対しユーザを一意に特定したい。 回答は例にしめすようにJSON形式で表示してください:要求文[{question}] 例: [{{ "user_id": , "last_mame": "", "first_name": "", "phone": "", "email": "" }}] """ prompt = PromptTemplate(template=template, input_variables=["question"]) db_chain = SQLDatabaseChain.from_llm(llm,db,verbose=True,output_key="Answer") return db_chain.run(prompt.format(question=user_text)) if __name__ == "__main__": print("\nお客様の情報を確認します。お名前、電話番号、ユーザID、メールなどお客様を特定できるデータを入力してください。") while True: user_text=input(">") user_json = find_user(user_text) try: users = json.loads(user_json) except: print("お客様の情報が確認できませんでした。もう一度入力してください。") continue if users is None: print("お客様の情報が確認できませんでした。もう一度入力してください。") continue if len(users) > 1 : print("お客様の情報が特定できませんでした。もう一度入力してください。") continue print("お客様の情報が確認できました。") break user = '\n'.join(f'{key}: {value}' for key, value in users[0].items()) #print(user)
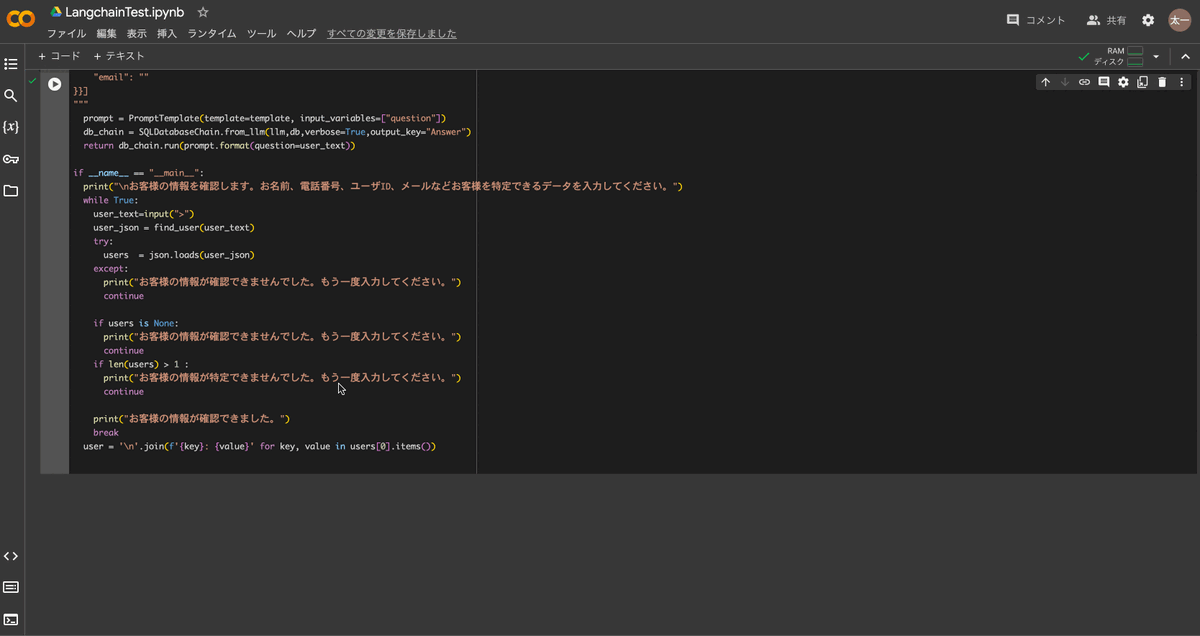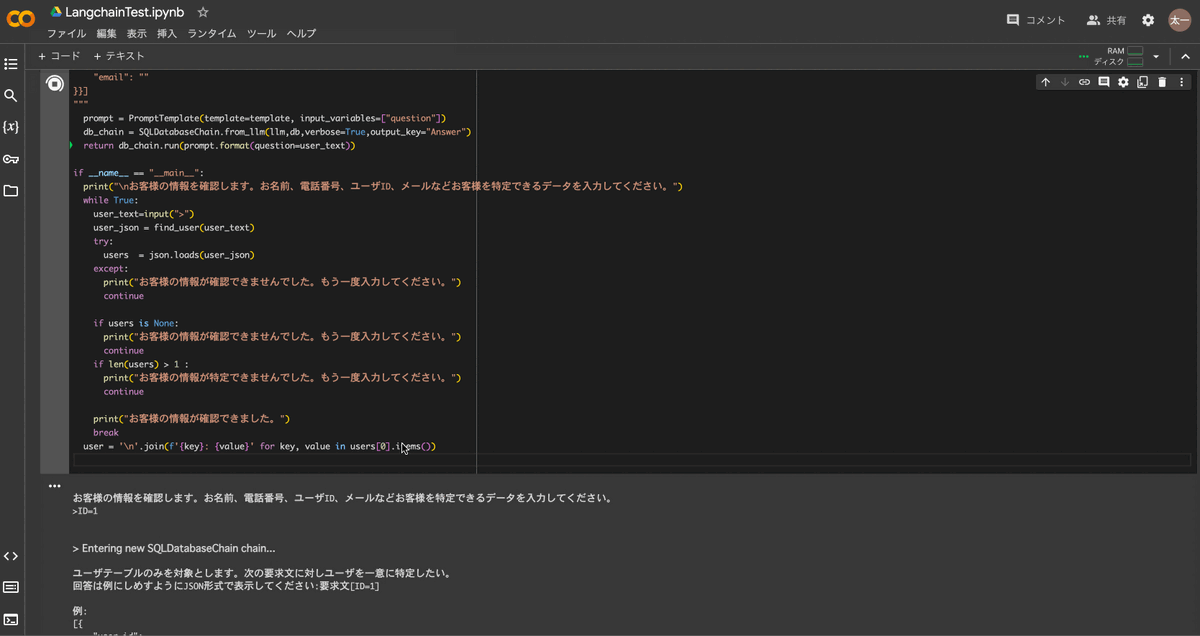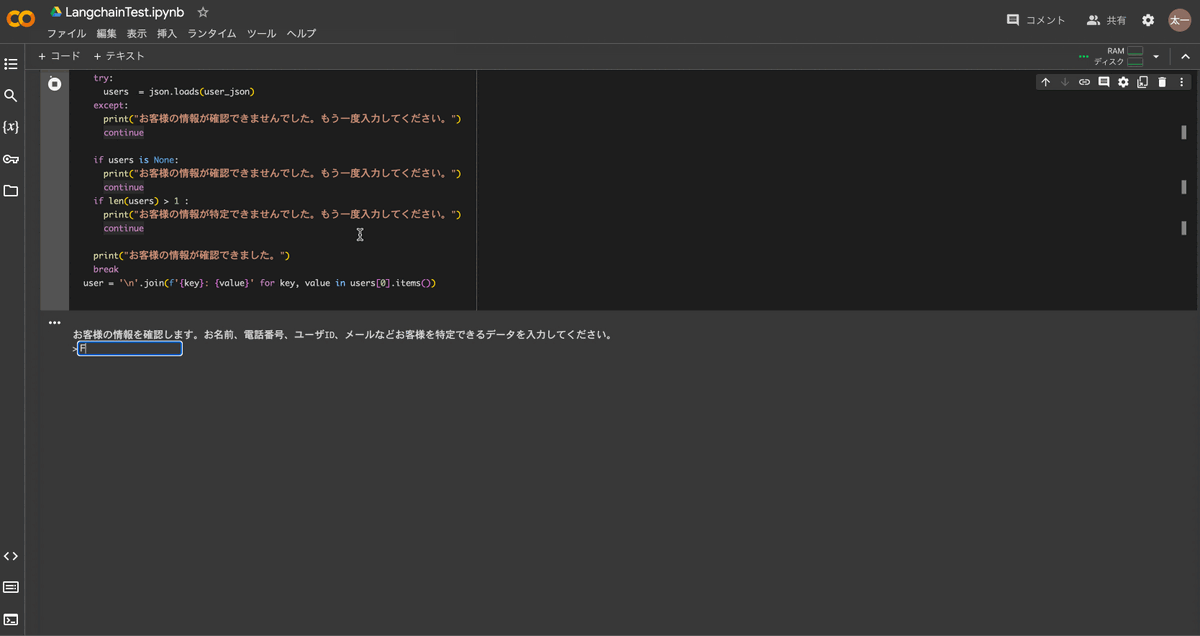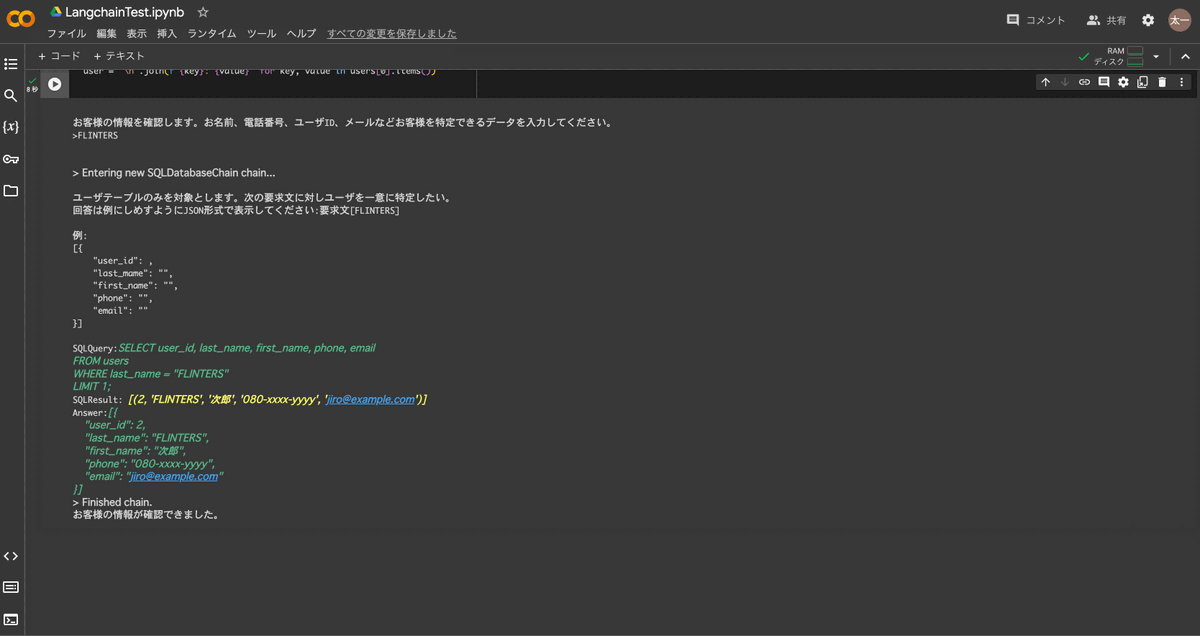
実行結果は以下のようになります。
IDや名称からユーザーを特定することができました。
② ユーザーに関する情報の全てを取得する
次に確定したユーザー情報をもとに、購入履歴と対応履歴を検索します。
from langchain_experimental.sql import SQLDatabaseSequentialChain def get_user_info(user): template= \ """ 次の要求文のユーザIDの広告名や価格も含めた購買履歴(テーブル)の内容を知りたい。 なお回答はヘッダー付のCSV形式で出力してください。: 要求文[{user}] """ prompt = PromptTemplate(template=template, input_variables=["user"]) chain = SQLDatabaseSequentialChain.from_llm(llm, db, verbose=True) order_history = chain.run(prompt.format(user=user)) template= \ """ 次の要求文のユーザIDの対応履歴(テーブル)の内容を知りたい。 なお回答はヘッダー付のCSV形式で出力してください。: 要求文[{user}] """ prompt = PromptTemplate(template=template, input_variables=["user"]) chain = SQLDatabaseSequentialChain.from_llm(llm, db, verbose=True) support_history = chain.run(prompt.format(user=user)) return f"購買履歴:\n{order_history}\n\n対応履歴:\n{support_history}\n\n" if __name__ == "__main__": user_info = get_user_info(user)
実行結果は以下のようになります。
user_infoに購買履歴と対応履歴が代入されていることが確認できました。


③ サポートを行う
from langchain.prompts import ( ChatPromptTemplate, MessagesPlaceholder, SystemMessagePromptTemplate, HumanMessagePromptTemplate ) from langchain.chains import ConversationChain from langchain.chat_models import ChatOpenAI from langchain.memory import ConversationBufferMemory template=\ """ ## ユーザ情報 {user} {user_info} ## 処理 あなたは接客のエキスパートです。お客様の要求文にたいして的確に答えてください。 接客のさい、上記のユーザ情報を参照し親切丁寧にお客様サポートをしてください。 ただし、わからないものに関してはわからないと答えてください。 """ system_template = template.format(user=user,user_info=user_info) prompt = ChatPromptTemplate.from_messages([ SystemMessagePromptTemplate.from_template(system_template), MessagesPlaceholder(variable_name="history"), HumanMessagePromptTemplate.from_template("{input}") ]) llm = ChatOpenAI(temperature=0.5) memory = ConversationBufferMemory(return_messages=True) conversation = ConversationChain(memory=memory, prompt=prompt, llm=llm) while True: command = input("質問をどうぞ(qで終了)>") if command == "q": break response = conversation.predict(input=command) print(f"{response}\n")
実行結果は以下のようになります。
ユーザーや購入履歴も把握することができているようです。

まとめ
本ブログにてLangChainで長文データを扱う技術、またSQLDatabaseChainでSQL問い合わせツールの検証を行いました。非常に単純な実装ではありましたが、今後もっと機能を拡充することさえできれば、DBでの自然言語での問い合わせやタスク間の値の受け渡しなどを自動化することができ、業務改善に新たな一手を予感させるほど魅力的な技術だと感じています。
FLINTERSの行動規範である『学びを結集し、新たな付加価値を見つけよう。』があるように、知識を昇華させ社内外に影響を与えられるようなエンジニアになれることを目標にまた今年からも精進して参りたいと思います!ブログをご覧いただき誠にありがとうございました!