日常の仕事をするためSublime Text
こんにちは、株式会社FLINTERSでFlinters Data Hubのプロジェクトマネージャー・プロダクトオーナー(以下PM・PO)をやっているTungです。 この記事はFLINTERS設立10周年ブログリレーの88日目の記事になります。 今回は通常の仕事をするため、よく使っているSublime Text を紹介したいと思います。
はじめに
私の日常業務では、主にMeta、Googleなどのメディアから取得した生データファイルと頻繁に作業することがあります。これらの生データファイルの特徴は:
- それぞれのメディアの生データファイルは、それぞれのファイル構造を持っており、同じメディア内でも複数種類のデータがある。
- 1つの生データファイルには非常に多くの情報が含まれており、手作業で迅速に情報を抽出することはできない。
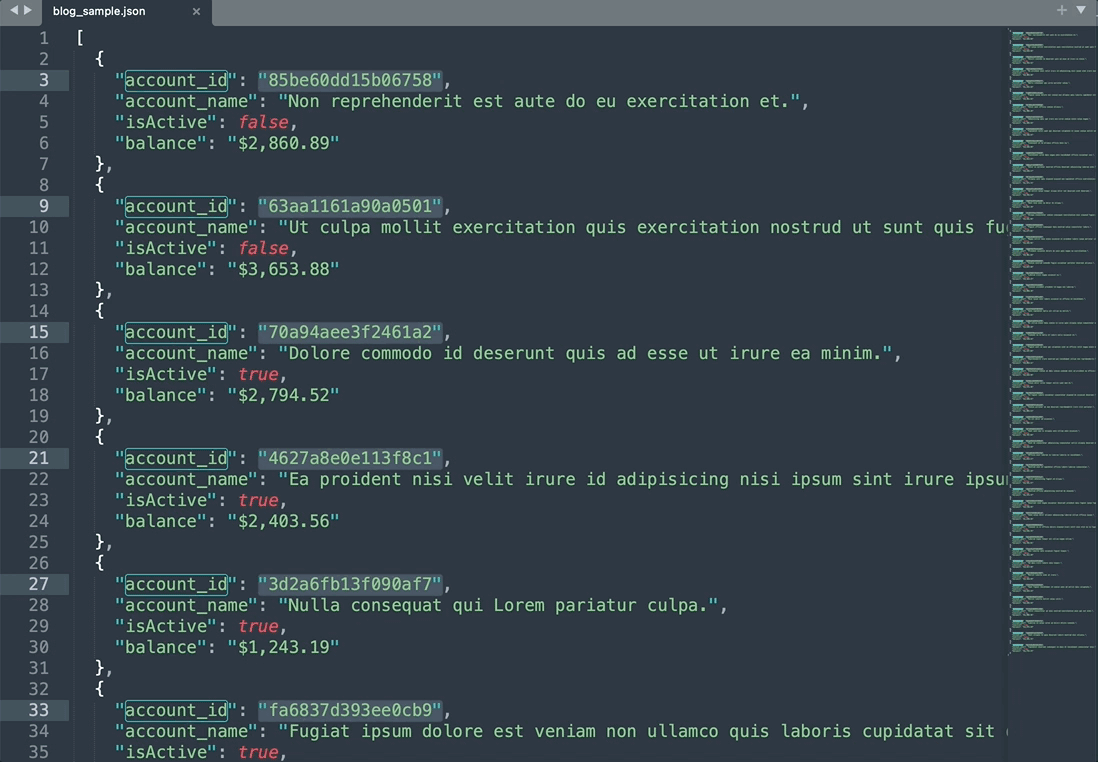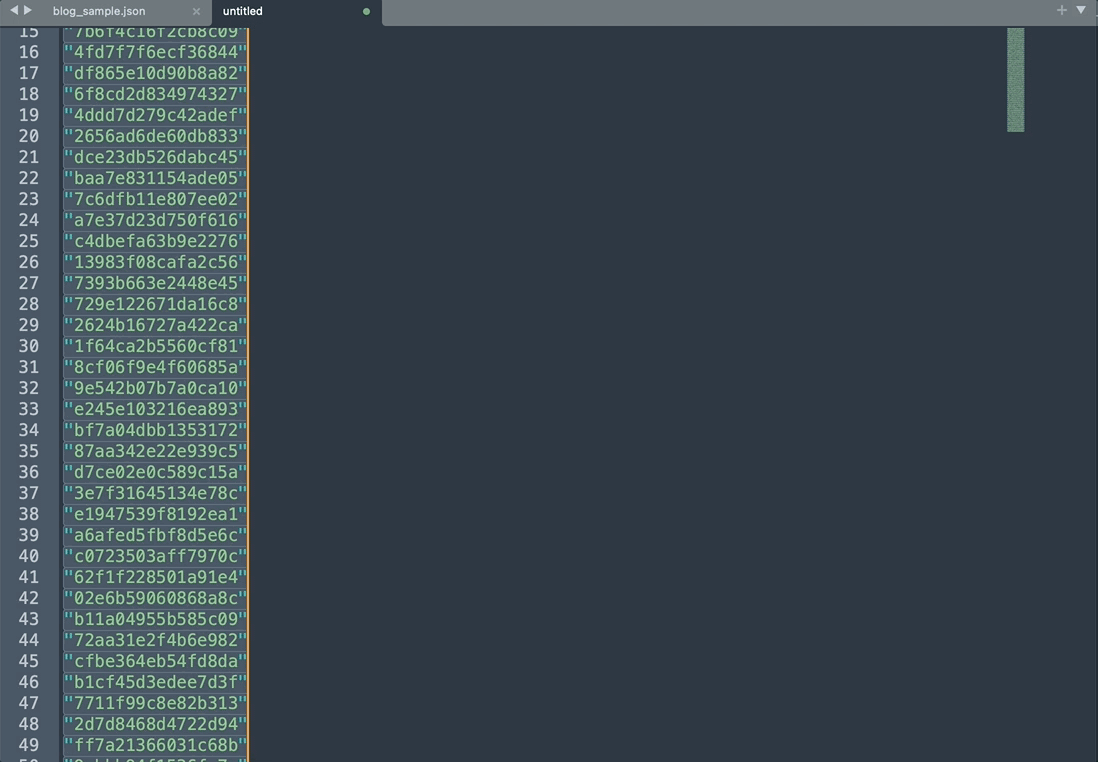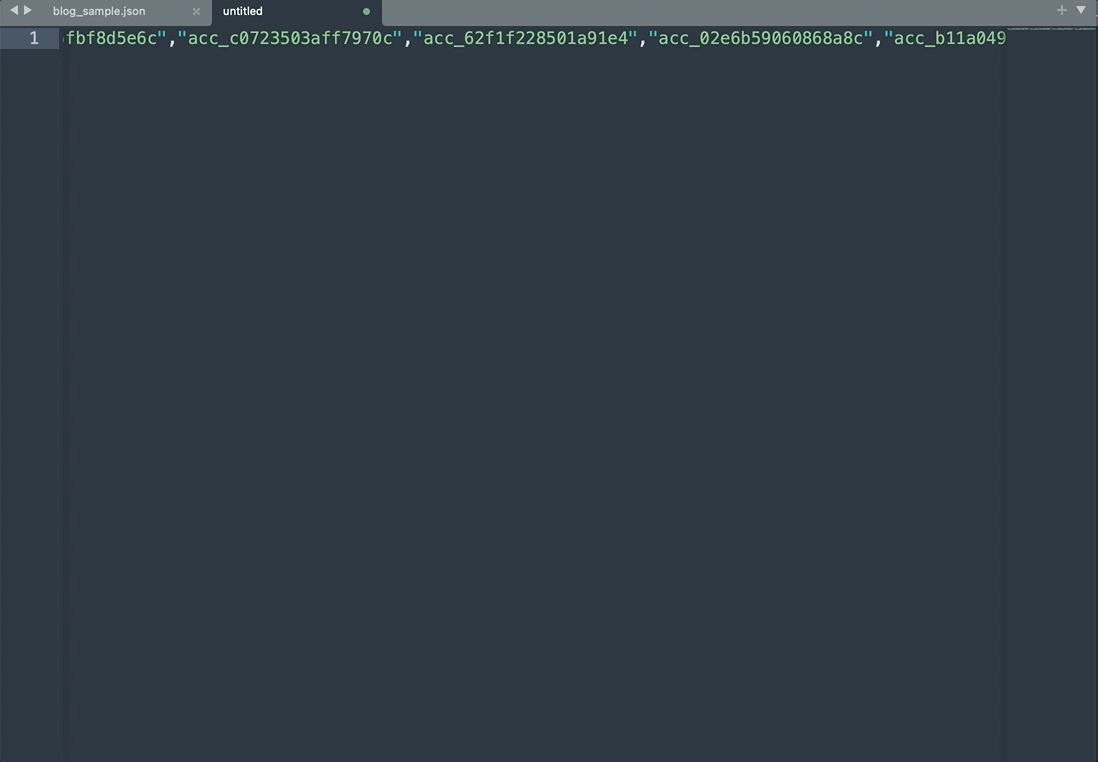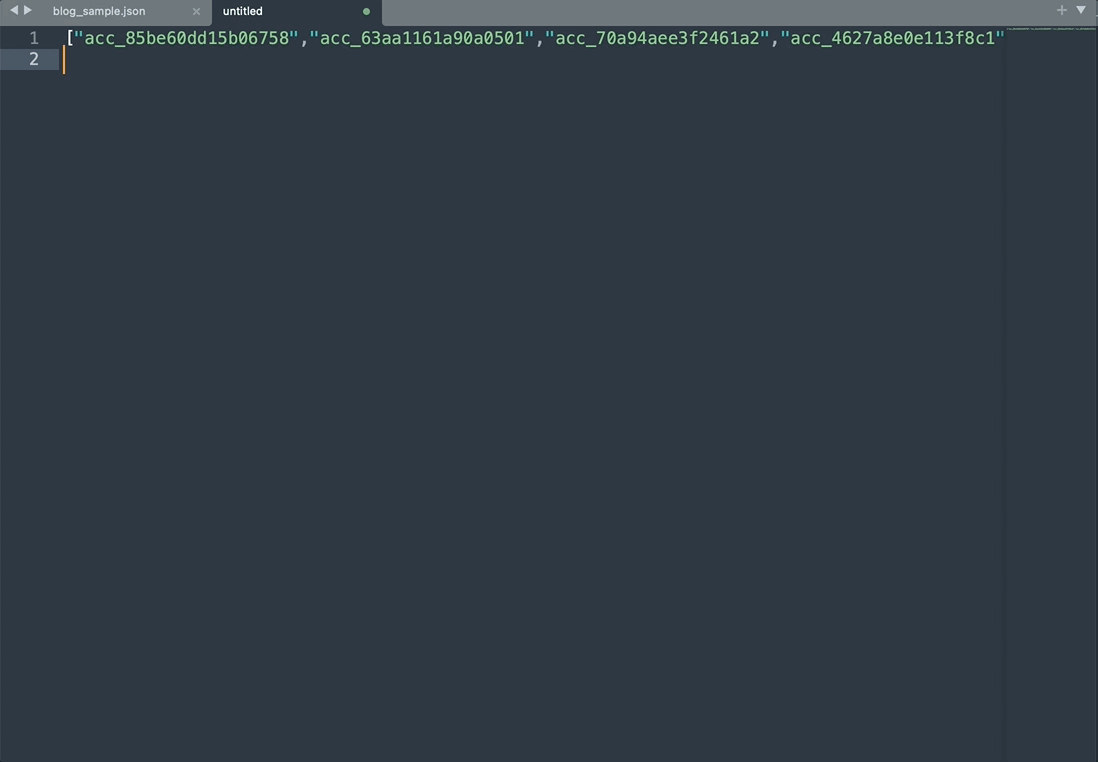
以下は、ランダムに作成された多くのオブジェクトを含むJSONファイルの例
[ { "account_id": "85be60dd15b06758", "account_name": "Non reprehenderit est aute do eu exercitation et.", "isActive": false, "balance": "$2,860.89" }, { "account_id": "63aa1161a90a0501", "account_name": "Ut culpa mollit exercitation quis exercitation nostrud ut sunt quis fugiat cupidatat nisi ipsum quis.", "isActive": false, "balance": "$3,653.88" }, { "account_id": "70a94aee3f2461a2", "account_name": "Dolore commodo id deserunt quis ad esse ut irure ea minim.", "isActive": true, "balance": "$2,794.52" }, { "account_id": "4627a8e0e113f8c1", "account_name": "Ea proident nisi velit irure id adipisicing nisi ipsum sint irure ipsum.", "isActive": true, "balance": "$2,403.56" } ]
課題
大規模データ処理システムがあったとしても、いくつかの場合では、エンジニアでないPOが迅速に調査または集約する必要があります。例えば以降の例記述 - メディアが未処理の新しいタイプのデータを生成する場合 - 異常が発生した場合、生のファイルから一括でデータを抽出して迅速に調査する必要がある場合 - 次の処理フェーズのinput情報を生成するために、一括でデータを処理する必要がある場合
具体的には以下のことを行なっています
- JSONサンプルファイル内のすべてのaccount_idを抽出する必要がある
- 一連のaccount_idに特殊文字を追加し、その後、カンマで区切られた配列の形でアカウントIDリストを作成、次のステップでの調査API呼び出しの入力として使用する
なぜSublime Text
この問題に関して、Sublime Textは要件を満たす適切なツールです:
- Window、macOS、Ubuntuを含む複数のプラットフォームで動作するエディター。
- 非常に軽量であり、大容量のJSONファイルを簡単に開くことができるため、大きなメモリを必要としません。
- 非常に素晴らしいマルチ編集モードを持っている。
よく使えるパータンの例
同じ項目の全てのデータ選択
- account_id項目選択
- 同じ項目の全て選択
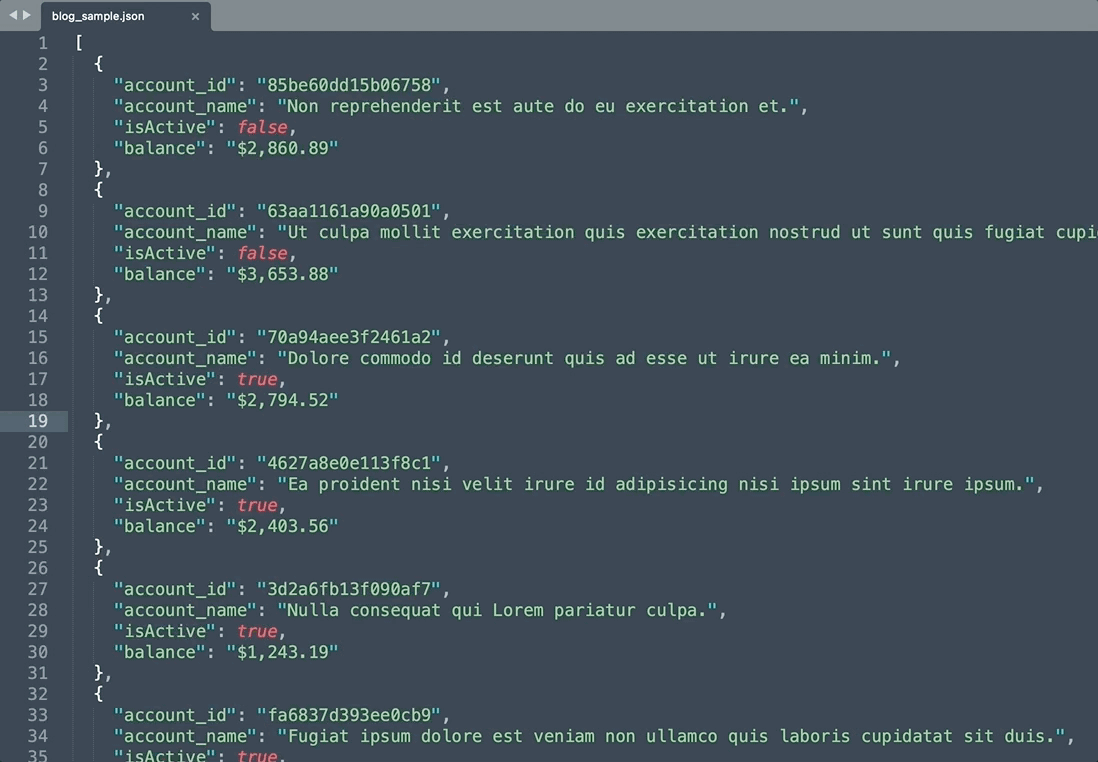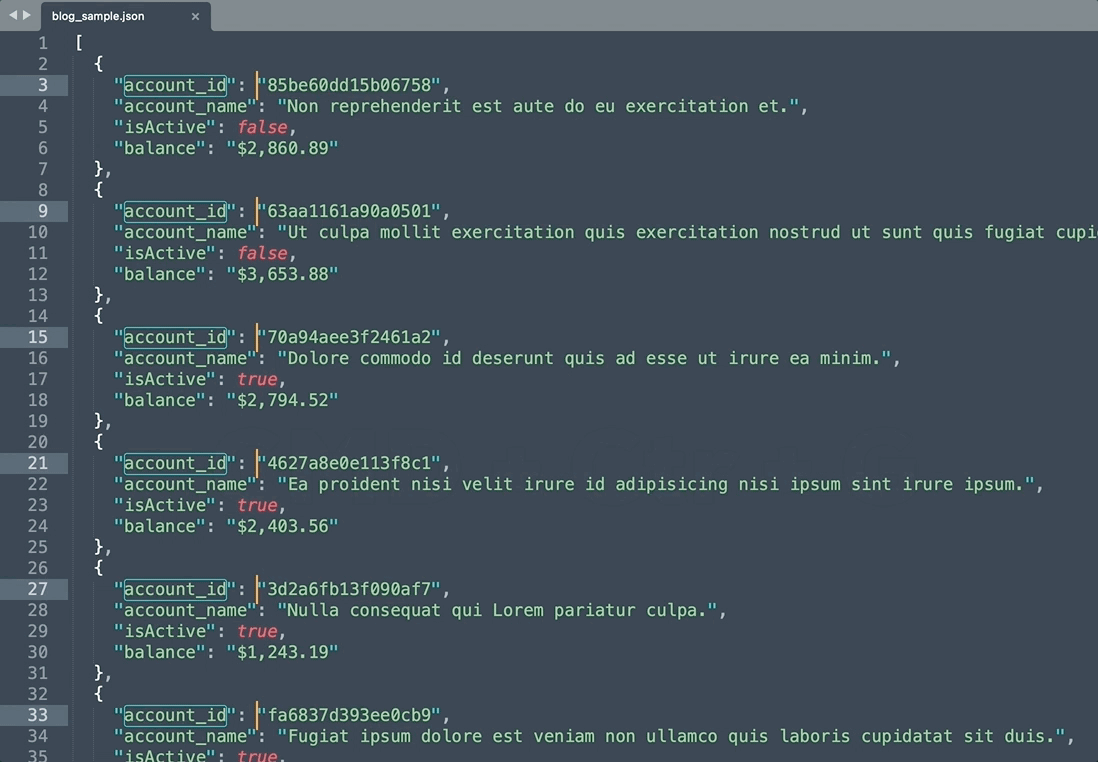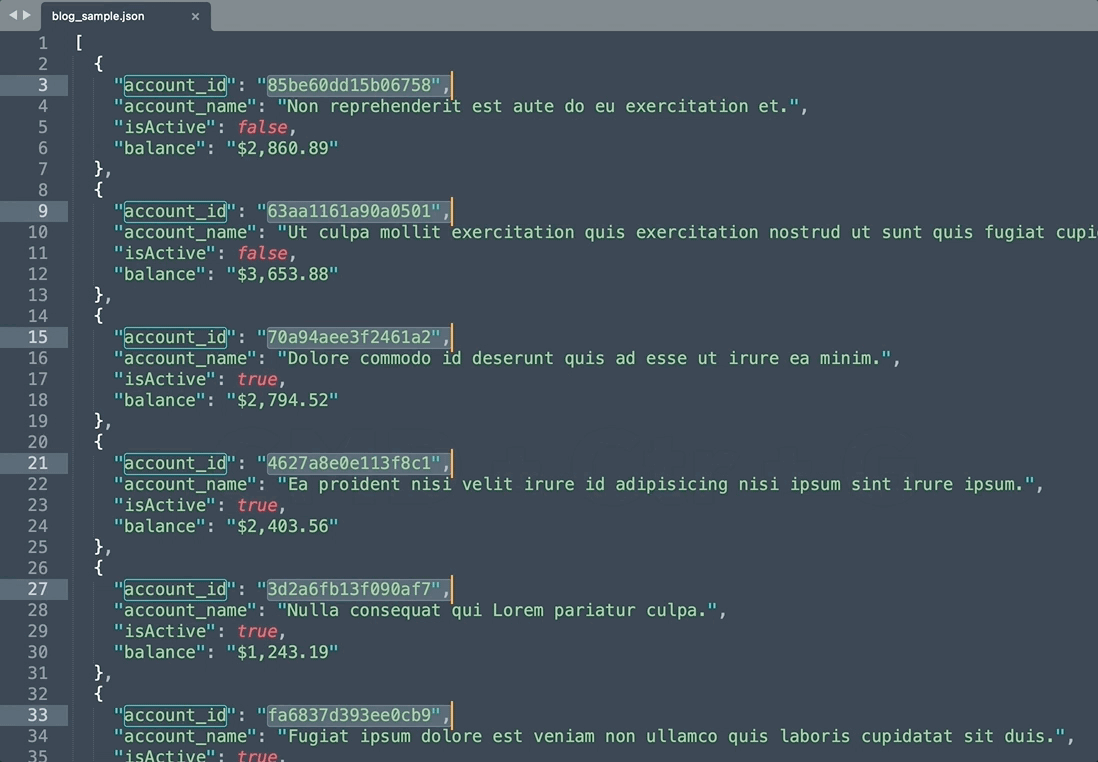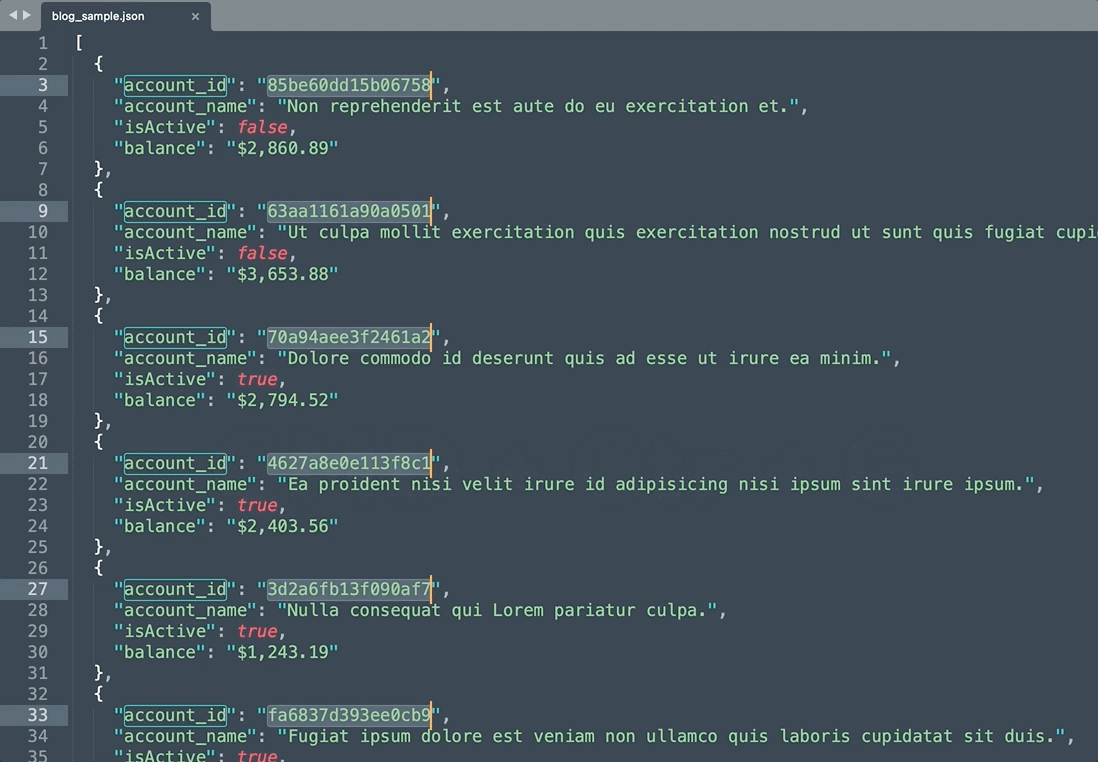
同時編集機能で操作
- 一連のaccount_idに特殊文字を追加し
- カンマで区切られた配列の形でアカウントIDリストを作成
操作に慣れれば、おおよそ5秒でアカウントIDリストを配列の形で作成できます。
結論
同時処理機能を備えたSublime Textは、上記の例のように柔軟に適用して、たくさんの問題をたった1つのシンプルなツールで解決できます。POとして、さまざまな要求を持つ生データを頻繁に調査する立場で、Sublime Textは私の日々の業務に大いに役立っています。