こんにちは、株式会社FLINTERSに出向中のおさないです。
本記事はFLINTERSブログリレー企画「梅雨にも負けないブログ祭り」の一環で、実務でCloud ComposerのSizingを行う際にどのようにして構成の値を算出しているのかというテーマで、参照している箇所と値を決定するプロセスについてまとめてみます。
注: 本記事が対象とするCloud ComposerはCloud Composer 2を指します。
Sizingの前提知識
Cloud Composer(以下Composer)のSizingに関係する環境構成の項目は以下になります。
- イメージのバージョン
- ワークロードの構成
- スケジューラ
- トリガラー
- ウェブサーバー
- Worker
- コア インフラストラクチャ
- 環境サイズ
- ネットワークの構成(この項目については、諸般の事情により今回は省略します)
以下はWebコンソール上から見える情報の例です。


Sizingになぜイメージのバージョンが関わるのかについてまず説明します。これはWorkerの同時実行のデフォルト値に対する計算が影響します。

上記のようにバージョンによっては同時実行のデフォルト値が変更されています。これはworker_concurrencyの値をオーバーライドすることによってデフォルト値から変更することも可能ですが、デフォルト値で使っている環境がある場合はイメージのバージョン(イメージに対応するAirflowのバージョン)に注意する必要があります。ただし、worker_concurrencyを高い値にするとスケーリングが意図した通りに動作しない可能性があります。

ここでデフォルト値を使うべきなのか、オーバーライドした値を使うべきなのか、オーバーライドするのであればどのようにその値を決定すべきなのかといった疑問が浮かんできます。このあたりはマネージドサービスであるComposerとAmazon MWAAでも事情が異なりますし、当然Airflowを独自に構成した場合でも異なります。つまりComposerでは公式ドキュメントにもデフォルト値以外で明確な値を算出する計算式がなく、検証によって得られた実測値をもとに調整しなければならないということになります。
Sizingの考え方
結論としては環境(使用しているOperatorや外部APIへのリクエスト有無等)による、となりますが実験的に以下のような表を用意してみました。
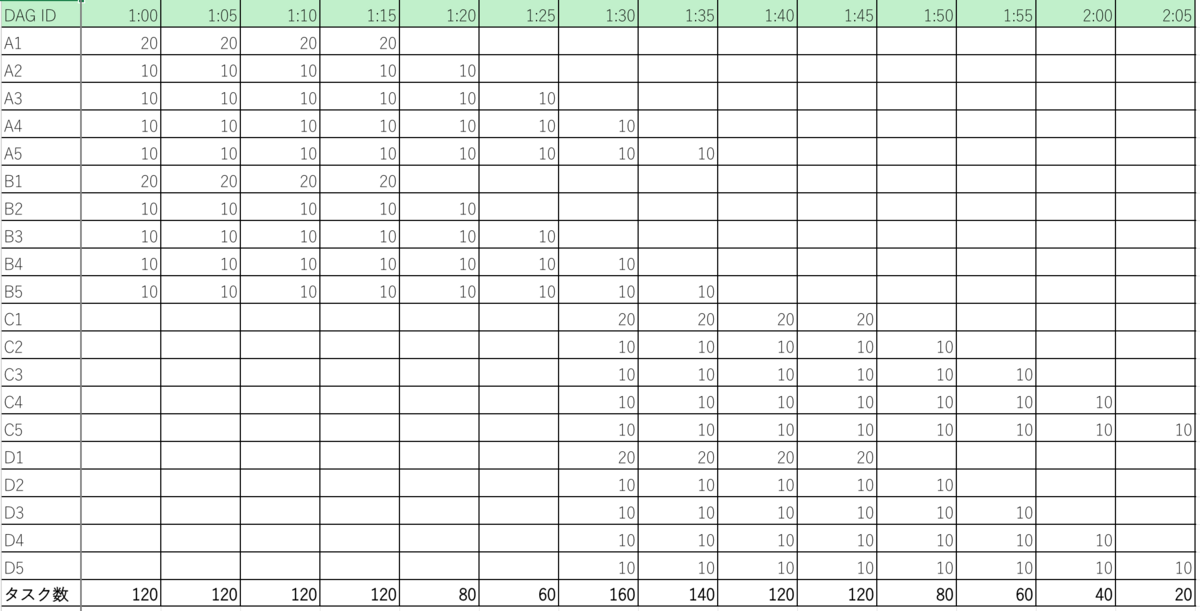
これは Monitoring や Airflow の Duration の値を参考値として5分ごとに同時実行されるタスクの数を単純集計したものです。実務ではTriggerDagRunOperatorやExternalTaskSensorによってこの辺りの集計値は大きく変動しますが、ここでは一旦考えないものとします。
全体を通してのタスク数の中央値は120であるため、ここを低コストなリソースで時間内に処理が終わるようにワークロードの構成を調整しつつ、タスク数が160〜140になる時点ではスケールして欲しいというのが基本的な考え方になるかと思います。ここで前述の自動スケーリングの仕組みを踏まえると、[celery]worker_concurrencyに120を設定していた場合、自動スケーリングによって新しいWorkerが増えるのかというと単純にそうはならないケースが多いです。
これはドキュメントにも記載がある通り、個々のタスクが小さく迅速に実行される場合(Durationが小さい場合)スケーリングが過剰になるという状態に該当します。より具体的な例としては、1つのDAGの中で、BigQueryInsertJobOperatorによるタスクは10分以上かかるのに対し、PythonOperatorは数秒で終わるようなケースです。では逆に[celery]worker_concurrencyを小さくしすぎた場合はどうなるのかというと、単純にタイムアウトが発生する可能性が考えられます。
加えて下流のタスクでPriority Weightが低くなっている場合は上流のタスクが優先されるため、上流のタスクでBigQueryInsertJobOperatorなどによる時間を要するタスクが複数あるとき、下流の迅速に実行されるタスクがなかなか実行されずDAGがタイムアウトを起こすケースもあり得ます。
以上のことから、ComposerのSizingにおいてワークロードの構成や[celery]worker_concurrencyなどの変更についてはMonitoringの実測値をもとに時系列でその時間帯にどれくらい時間のかかるタスクが実行されているかを調査し、Workerのリソースについての過不足やPriority Weightによる実行順を加味した上で決定する必要があります。地味な作業にはなりますが、各DAGごとに時系列で情報を整理しどのタスクに時間がかかっているのか、どの上流タスクが下流タスクに影響を与えているのかを明らかにしなければ費用面含め適切なSizingは難しいということになります。
おわりに
ComposerのSizingは実務での環境において差が大きく、DAGが数百タスクが数千しかも24時間365日動いている環境(常に高負荷)もあれば、DAGが数十タスクが数百で日に数時間だけ動く環境(瞬間的に高負荷)もあり一様に適切な値を算出する計算式をこれですと出せないのが個人的に申し訳なく感じるところです。
しかし時系列でしっかりと調査しコスト最適化、パフォーマンス最適化など複数の観点で情報をまとめて提案できれば将来的な事故防止や修正に強い環境が作れることは間違いありません。そのためにはやはり地道な調査や、今の視座・視野がそのプロジェクトに適しているのかなどを常に気にしつつ地道に着実に積み重ねる他ないと考えています。
参考
環境のパフォーマンスと費用を最適化する | Cloud Composer | Google Cloud
環境をスケーリングする | Cloud Composer | Google Cloud
DAG のトラブルシューティング | Cloud Composer | Google Cloud
Airflow Scheduler に関する問題のトラブルシューティング | Cloud Composer | Google Cloud